AI 无处不在、随时在线和以数据为中心的时代,正催升对更高带宽的需求,而这已经超出了当今技术和产品尺寸的能力范畴,世界需要一种当前 CPU 和 GPU 技术所无法企及的更高效、更普适的计算, 自适应计算应运而生。
北京:AI 无处不在、随时在线和以数据为中心
金钱算什么,数据才是推动当今世界运转的王者。从远程物联网终端为城市规划、健康跟踪、环境保护、业务改进等多样化用途采集数据,到我们热衷的视频流内容和在线分享生活,数据的迁移、管理和分析,正处于所有功能的核心,也促使消费者更广泛地使用随时在线的个人物联网设备,并让企业和科研越来越依赖以 AI 为中心的应用。
数字化的生活方式和新兴的物联网与云端计算及数据服务的快速增长密不可分。云是全新的生活与工作方式的中心。它存储着海量的个人内容,供人们随时随地进行访问;它托管点播音乐和视频流服务;它采集和分析工业数据或企业数据;它将功能强大的软件应用以按次计费的方式低成本地提供给金融分析、数据库搜索或基因组测序等工作使用。
此外,5G New Radio( NR )引入了对海量机器通信( MMTC )和超低时延通信( ULLC )的支持,能实现全新的实时蜂窝通信服务。而这 将给回传网、城域网以及核心网的容量和性能带来巨大压力。
核心基础设施面临越来越大的压力
如今,提高数据带宽和计算吞吐量是所有的云数据中心、电信网络和蜂窝通信回程网共同面临的强劲需求。涉及的主要基础设施组成部分包括进出数据中心的链路、连接地域分散型数据中心站点的数据中心互联( DCI )、基础设施接口卡和加速器卡。事实上,核心基础设施对数据带宽的需求名义上是以 51% 的年均复合增长率( GAGR )增长,然而,单是 5G 的推出便可推动区域流量容量需求增长 100 倍。
利用协议处理芯片和接口芯片等分立组件打造新的、更高性能的设备来满足这些需求,不仅复杂费时,而且越来越难以按照性能需求进行扩展。此外,采用这种方式设计出的系统体积庞大、功耗惊人,无法满足数据中心和基础设施设备对空间占用、功耗和热管理的限制性要求。新一代设备必须在现有的物理、电气和热约束条件范围内大幅提升性能。
除此之外,设计工作需要在最终规格商定之前采用非常先进的协议和标准,才能率先投放市场,尽早抓住机遇。对于想要率先将产品投放市场的设备提供商而言,等待标准成熟之后再部署肯定是无法实现领先的预期, 只有拥有能够随着项目的进展在硬件层面灵活地适应变化的能力,才能与时俱进领先同行。
具有突破性意义的可编程加速器
对于一些使用传统 CPU 或 GPU 架构无法快速执行或功耗约束得不到满足的工作负载,高密度 FPGA 和异构的可编程片上系统 IC( MPSoC )等可编程逻辑器件已成为理所当然的加速器选择。这些器件不仅可以通过高度并行的处理模式以极为高效的方式解决特定计算难题(例如信号处理和近期的神经网络),而且还提供了可编程器件固有的灵活应变能力。
现在,为了满足近来日益严苛的性能、带宽、功耗和集成目标,被称为自适应计算加速平台 ( ACAP )的新型可编程器件已经问世。赛灵思 Versal™ ACAP 内置一系列智能 AI 和 DSP 计算引擎、等效于 FPGA 逻辑架构的自适应引擎,以及应用处理和实时标量引擎,并通过片上可编程网络( NoC )互联紧密耦合。它还集成了软件控制平台管理功能和众多先进的接口,包括 DDR4、100G 以太网、PCIe® Gen 5 和数千兆位光通信接口。
Versal DSP 引擎采用经过改进的 DSP 块,为 INT8、32 位浮点等操作数提供本机支持,从而提升了多种应用的速度和效率,不仅包括数字信号处理,而且也包括宽动态总线移位器、存储器地址生成器、宽总线多路复用器以及存储器映射 I/O 寄存器。标量引擎由一个双核 Arm® Cortex™-A72 应用处理器和一个双核 Arm® Cortex™-R5F 实时处理单元构成。ACAP 的异构引擎能够实现重新编程,以适应随时间推移而变化的工作负载,或是随着算法实现或神经网络模型演进而变化的工作负载。
优化 ACAP 连接性
依托于这种新型可编程器件助力实现的创新,Versal Premium 系列现已能够应对当今核心基础设施面临的压力。这些高带宽器件将高计算密度与附加的专用高速加密( HSC )引擎以及先进的网络接口相结合。
高密度网络连接功能包括:提供总双向带宽高达 9Tb/s 的可扩展光纤收发器(支持最新的以太网和 Interlaken 速率与协议)、112Gb/s PAM4 收发器、加密处理能力高达 400Gb/s 的高速加密引擎,以及灵活应变的硬件(图 1)。
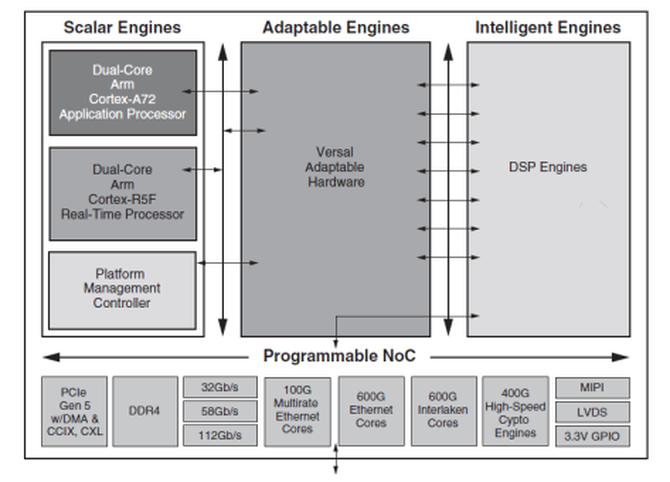
图 1:配备有 112Gb/s PAM4、600G 以太网、600G Interlaken 和 400G HSC 的 Versal Premium ACAP。
与现有的 58Gb/s PAM4 技术相比,在核心网、城域网和 DCI 基础设施中采用 112G PAM4 收发器能够使每端口带宽密度翻倍,从而缓解前面板机柜空间的压力,并为电信和数据中心应用加倍提供单位体积带宽。与此同时,给定的数据有效载荷的传输时延降低 50%,提高了应用的响应能力,有助于降低时延对地域分散型数据中心互联的影响。
较之赛灵思 16nm Virtex® UltraScale+™ FPGA,片上集成资源提供了高达三倍的带宽和两倍的计算密度。另一方面,与专用的特定应用光传输网络( OTN )处理器相比,应用吞吐量提高了三到五倍。
提升计算密度
为了满足超大规模云服务提供商的当前及未来需求,Versal ACAP 架构将极高的片上存储器带宽与高性能异构计算引擎紧密耦合,并通过动态功能交换( DFX )实现灵活的工作负载配置。与之前的 16nm FPGA 相比,DFX 交换内核的速度加快了八倍,支持加速器的动态配置,从而最高效地将器件资源用于随时间推移而变化的计算工作负载,如数据分析、机器学习视觉处理、基因组学、视频转码、加密处理等。
凭借多种类型的分布式片上 RAM,高达 1Gb 的紧密耦合存储器可供使用,进而提供了最高 123TByte/s 的等效片上存储器带宽。该带宽能实现各种处理引擎与存储器之间的高速交互,其速度比如今最优秀的 GPU 快九倍。此外,可编程 NoC 互联支持与片外 DDR4 存储器进行高速交互。
Versal Premium ACAP 能够满足 DCI 设备的需求,兼容服务器侧和传输侧的多种光通信接口与协议,同时以安全、低成本的平台灵活适应新兴的且不断演进的标准。1RU 系统或单卡就能提供 3.2Tb/s 的容量,支持多种多样的标准化和新兴协议以及光通信接口(图 2)。凭借其先进的连接和加密核心,单个 Versal Premium ACAP 器件就能为服务器侧的光通信接口提供 4x25G NRZ 连接的多条 100G FlexE 以太网通道、为线路侧提供 4x112G PAM4 连接的 400G 以太网通道、线路速率为 1.6Tb/s 的 AES256 加密、控制和端口管理功能。
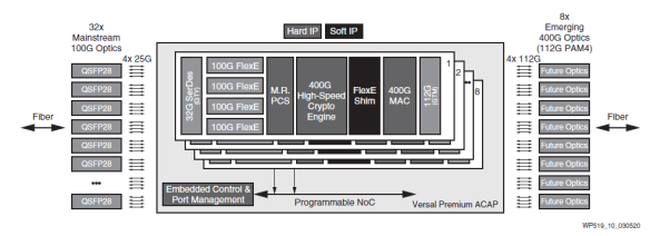
图 2:采用 Versal Premium ACAP 的 3.2Tb/s DCI。
这些器件也非常适合用于高速客户端接口卡(图 3),具体方式是利用 Versal Premium ACAP 将数据流量与服务桥接并封装到行业标准的 OTN 封装程序中。Versal Premium ACAP 内部集成通道化以太网、Interlaken、112G 和 58G PAM4 GTM 收发器与 32.75G GTYP 收发器,提供每秒多太位容量。这些资源以专用硬 IP 的形式集成,既能获得 ASIC 级的功率效率,又能释放 ACAP 逻辑架构用于映射、开销和 SAR 功能。
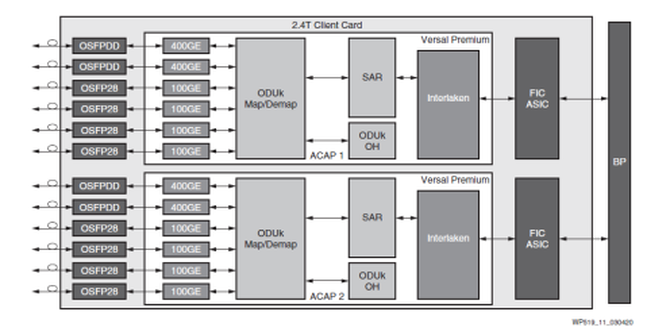
图 3:2.4Tb/s 客户端接口卡。
面向未来的 AI 加速
通过将异构计算引擎与高存储器带宽相结合,Versal Premium ACAP 在处理高难度工作负载(如使用神经网络开展图像分类或对象检测)时,性能显著优于 GPU。图 4 对比了Versal Premium 与领先GPU 的性能,可以看到运行在 680x680 YOLOv2 模型上的对象检测速度在 ACAP Premium 器件上能提速高达 7.7 倍。
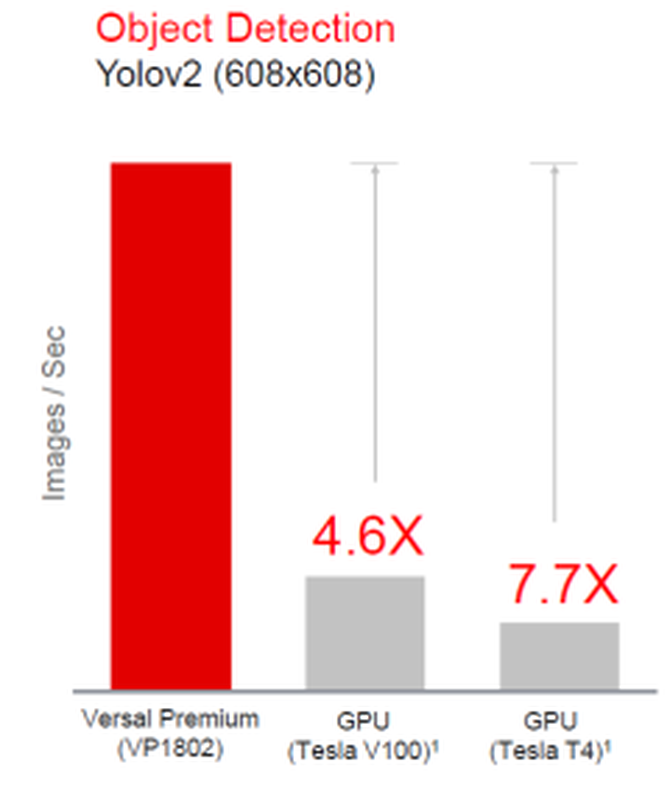
图 4:与 GPU 进行对比的对象检测性能。(NVidia 数据中心深度学习产品性能:https://developer.nvidia.com/deep-learning-performance-training-inference)
与 FPGA 和 MPSoC 架构相比,ACAP 另一个有助于简化加速器开发的引人瞩目的特性是预先构建的外壳程序,通过它能硬连接到片外接口,如以太网、PCIe Gen 5、DDR4 和光通信接口(图 5)。这种高效的云连接基础设施提供了多重优势,包括允许在设备启动时进行 CPU 主机和系统存储器通信、简化内核布局与时序收敛、简化加速器虚拟化。外壳程序便于设计人员将器件的内部逻辑架构更多地用于定制功能,否则就需要实现必要的基础设施,如存储器和 DMA 控制器。
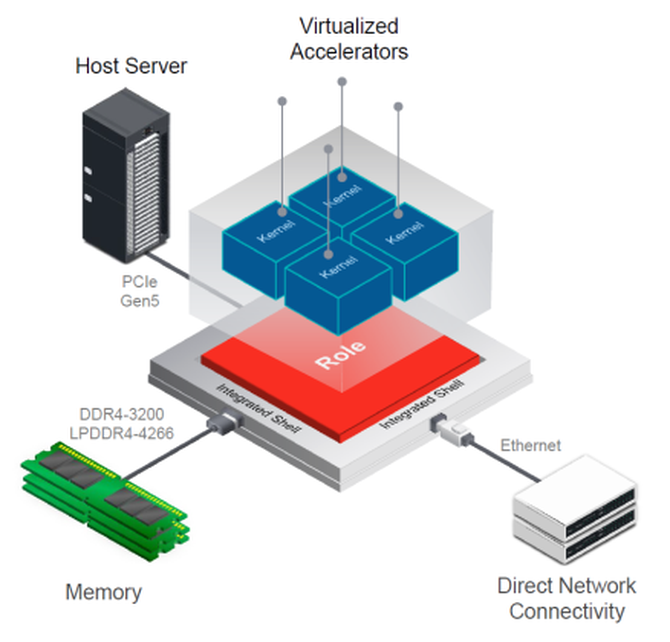
图 5:预先构建的外壳程序基础设施简化了云连接,同时实现了速度与效率的双重提升。
外壳程序和角色架构可以帮助设计人员快速高效地在 Versal Premium ACAP 中实现先进的智能零售技术。ACAP 器件支持数据驱动的视频内容分析,有助于降低损失以及提供自动、实时、可执行的库存洞察,并提供可促进销售最大化的客户体验定制能力。借助 Versal Premium ACAP 能够在单个平台上托管视频分析解决方案,用于视频元数据的识别、提取和分类(图 6)。
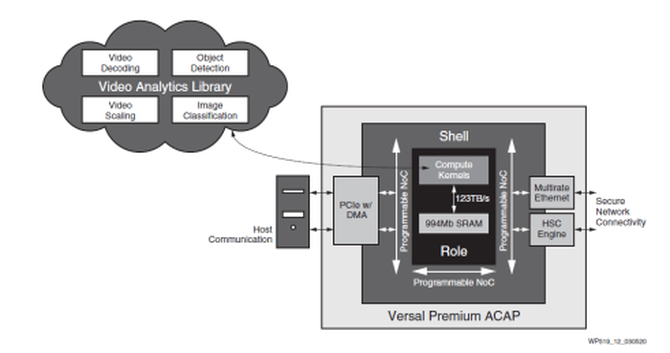
图 6:智能零售视频分析加速器。
外壳程序提供了现成的连接与加密功能,而器件的 DSP 引擎和软件可编程计算内核则可处理对象检测、图像分类以及视频编码、解码和缩放。而且能够在紧邻计算内核的地方提供最大 1Gb 的片上 SRAM,面向 AI 加速提供高达 123TB/s 的存储器带宽。通过消除 GPU 架构和基于 GPU 的架构所特有的存储器瓶颈与批次大小限制,分析加速器能够为 Resnet50 提供高达每秒 13,000 幅图像/秒的处理速度。
结论
尽管消费者和企业界越来越重视数据的价值,客户也越来越依赖于即时服务交付,但复杂性、计算强度和带宽耗用正成为瓶颈。ACAP 将高效的分布式异构计算引擎与高速互联融为一体,以满足飞速增长的性能需求。通过综合运用硬 IP、预先构建的创新型连接外壳程序、可编程逻辑架构和软件可配置资源,ACAP 器件不仅能够助力提升性能,还能简化设计,同时提供面向未来的灵活性。

