本期分享嘉宾

张浩
第四范式 资深体系架构科学家
【嘉宾介绍】博士毕业于新加坡国立大学数据库系统实验室,深耕数据库领域十余年,在国际排名靠前的数据库期刊/会议(VLDB, ICDE, TKDE)上多次发表论文/发表学术演讲,主要研究方向为内存数据库、软硬结合加速数据库系统性能等。加入第四范式后,主要参与大型系统架构设计、机器学习数据库等项目的研发。
分享大纲:
1、人工智能工程化落地的数据和特征挑战
2、OpenMLDB:线上线下一致的生产级特征平台
3、高可用在线执行和存储引擎
4、发展历程与未来规划
人工智能工程化落地的数据和特征挑战
第四范式基于100多个实际落地场景,开发了针对机器学习高效供给正确数据的数据库OpenMLDB,面向离线模型开发和面向在线推理的特征计算,在保证性能需求的前提下,需要产出一致性结果。基于线上线下数据一致性的新挑战,第四范式自研了面向机器学习的数据库。
其中,如何保障线上推理服务数据供给的高可用和低延迟,是设计此数据库的最大技术难点之一。做 AI 的同学可能知道,数据并不等于 AI。但是在数据上面花的时间精力,可能据统计达到95%。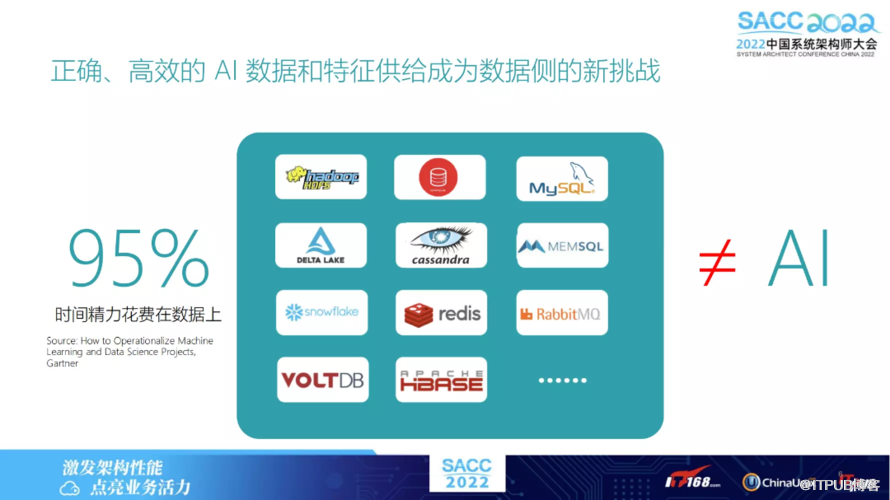
其中几方面主要包括比如数据源、数据清理,以及从源数据中如何生成需要表达的格式,从表格中提取出所需要的特征,以及如何快速对其特征进行一些线上的服务。再根据一些了解,尤其是一些银行或是金融客户,目前经常会做一些机器学习类的决策。
比方做一些超交易,会判断该笔交易是否为欺诈交易,交易发生过程中,需要做一定决策,也即”适中决策“,而非交易发生后再做是否为欺诈的判断。
其中会用到现在比较火的“硬实时计算”,它比流式计算中的延迟要求更高。流式计算中延迟要求可能为秒级别,而硬实时计算中,则在毫秒级。
下图列出了机器学习应用的全流程,主要包括两部分:离线开发、线上服务,且分别包括三个模块。
先是数据的采集存储;中间是如何从原始数据中提取出特征;模型的训练。
线上是模型的推理,假设完成离线开发之后,就会涉及线上部署,如何将离线模型部署到线上服务,再在线上服务对于实时的数据流进行接入,实时数据流接入后,可以把实时特征给计算出来,再 feed 进模型中,用于模型推理。
其后 OpenMLDB 做的主要关注点是在特征方面,即如何能够高效且一致地将特征 在离线、线上服务上高效计算出来。
通过下图展示一个特征通常是什么样子的,假设有一个银行刷卡的记录的场景,再假设在某个时间触发一个刷卡的操作,此时就需要实时去查询,查询当前卡号对应的历史表,可能会统计出当前该卡号比方10秒钟交易中的可能平均数,或是包括3小时交易的次数,再用这些特征判断该笔交易是否为盗刷或是欺诈交易。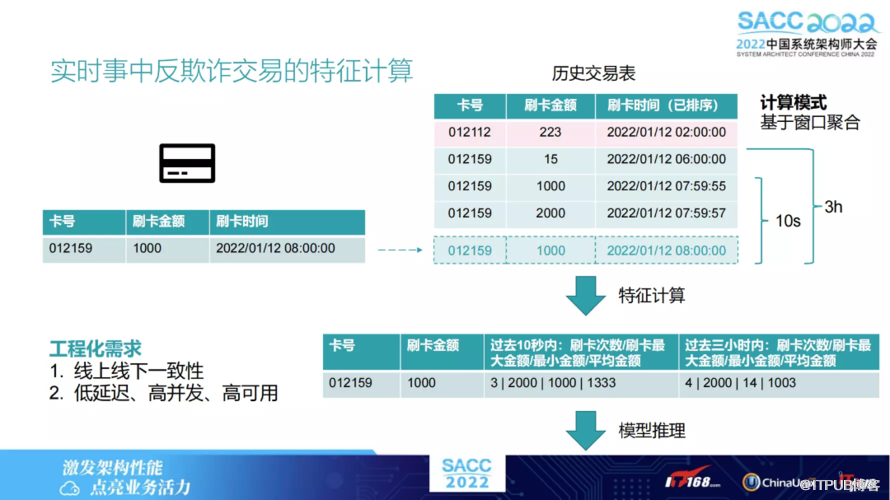
但是在此应用场景下,对于工程化的需求主要两个方面:
线上和线下计算特征必须保持一致,也即线下计算出的用于模型训练,这种特征和线上可以完全一一对应上的便无任何误差。
对于线上服务来讲,需要一个低延迟高并发,同时也有高可用的需求。
其中还有一点,通常来讲都是基于时间窗口的特征。比方上述例子一个10秒的或3小时的窗口做聚合特征,在机器学习期里实为比较常见的一个特征或例子。不难发现,较大的工作量是在一致性校验上。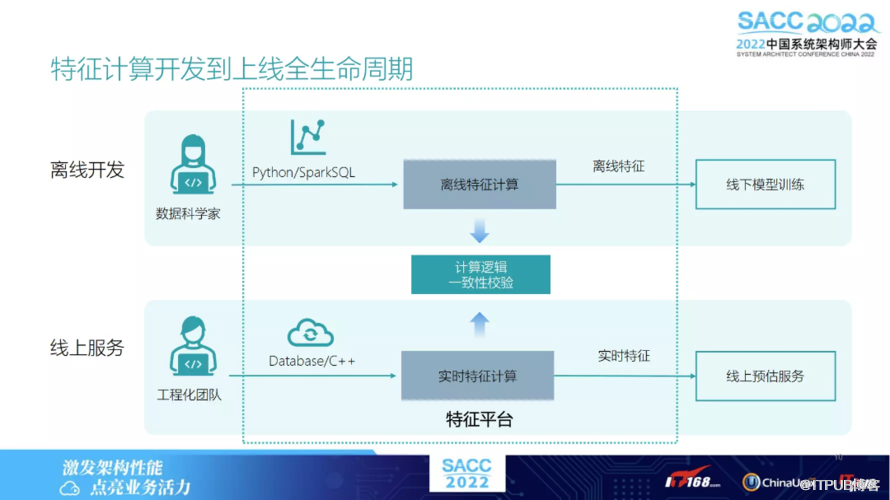
其历史原因为何?通常离线开发由数据科学家来做,对于该性能可能他并不 care,可能比较熟悉 Python 或 SQL,而直接用这些脚本语言把特征从原始数据提取出来,用于离线模型训练。
但是若涉及到上线,则需关注该性能,在一定的延迟内把特征计算出来,此时就需要一个工程化的团队。该团队负责通过高效的一个语言或是框架,把离线计算特征的逻辑 翻译成更高效的实时特征计算的逻辑。而翻译的过程,可能会出现不一致性。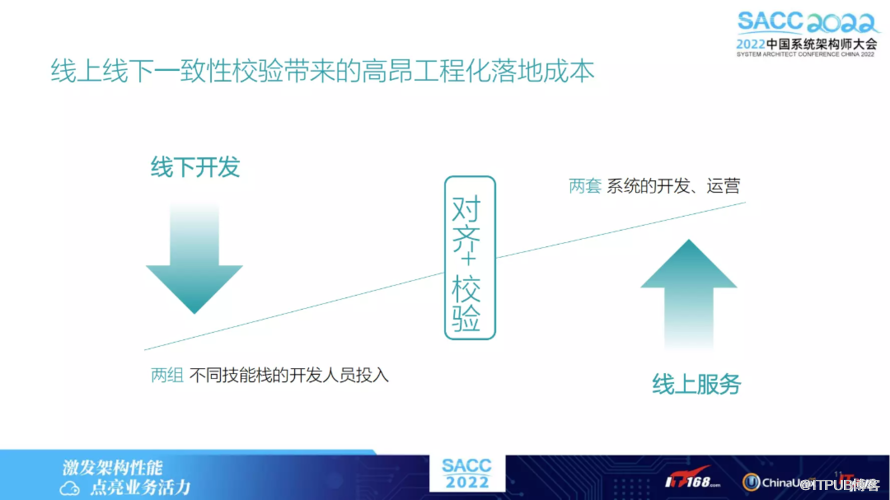
同时不同语言、不同框架,也会引起计算特征可能会有些差异。举个简单的例子,假如对0或对空值处理,其中一些细小差异最终在模型上,可能就会引发一些不常见的错误,甚至会造成一些线上故障。
因此线上线下一致性校验上,有着比较高额的落地成本,可能不同的开发人员以及技术栈,造成了线上验证工作的高耗时。对于这种特征计算平台,有不同解决方案。
OpenMLDB 提供的是一个开源解决方案,相当于提供开源、低成本、高效的企业级解决方案。对于有机器学习案例的客户,可以提供一个特征计算的高效平台。
OpenMLDB:线上线下一致的生产级特征平台
下文将阐述OpenMLDB如何做到线上线下一致性,以及保证线上达到低延迟。
OpenMLDB的发展历史
下图展示了OpenMLDB的发展历史,它于2021年6月开源,此前是闭源系统,范式里它被称作RTIDB/FEDB。还是闭源的系统之前,其实已有诸多场景落地。2021年我们决定将此特征平台开源出来,叫做OpenMLDB。
下图为OpenMLDB 的架构图,分为两部分:
离线的处理引擎。叫做 P 处理的SQL 引擎,它是基于 Spark 开发的,并在其基础上做了优化;
实时的 SQL 引擎,这完全是我们自研的一个实际数据库。
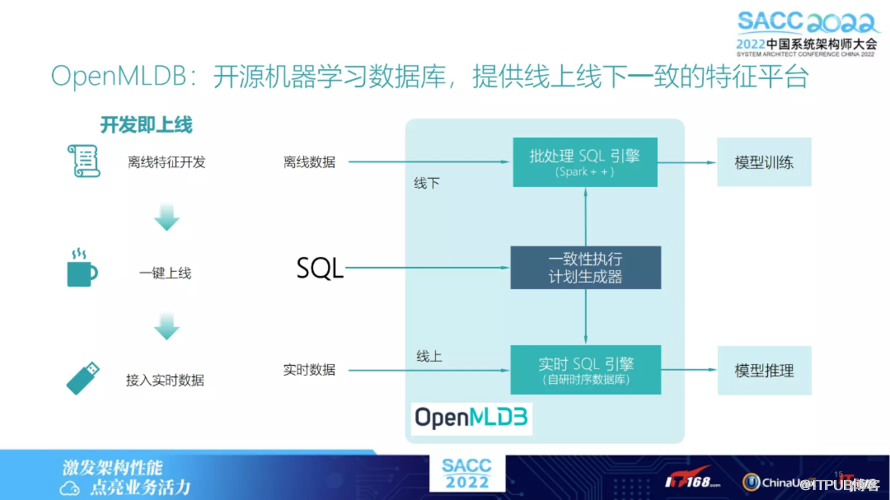
其中离线和在线会共用一套,即一个执行计划生成器。我们共用一个执行引擎,进而可以保证计算出来的特征完全一致。
另外为了简化工程落地上线难度,无需再进行一些复杂操作。我们只提供了一个脚本语言叫做 SQL,不管是离线特征开发还是线上,完全用一套 SQL 做开发。所以离线中若完成了离线的开发后,通过一键上线即可将实时数据接进来,做一些实时特征的计算。
下图列出了如果用 OpenMLDB,如何从离线开发到线上服务的完整流程 。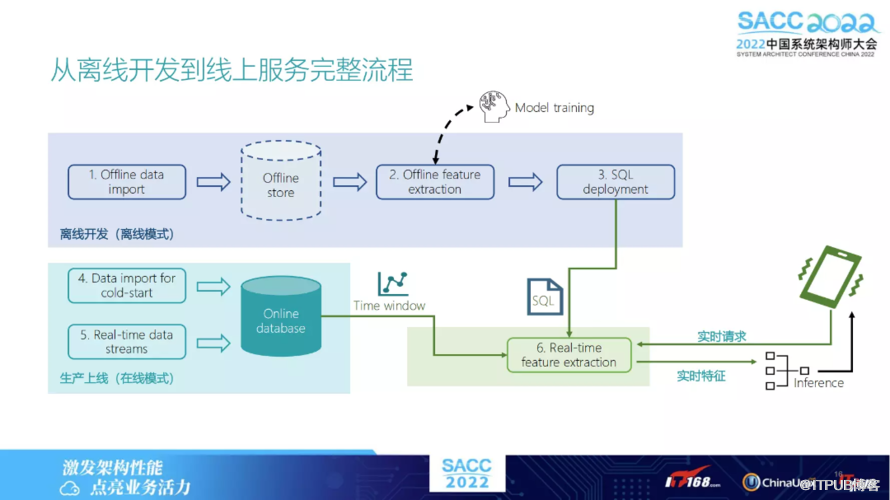
先是关于数据的处理,我们有一个离线的数据存储,假设既可用本地存储,也可用 HDFS 。其中离线特征的抽取,是用我们自己发行的 Spark 版本,抽取完之后,这些特征会用作离线的模型训练,训练好之后即可生成一个比较好的模型,再将 SQL 抽取脚本 deploy 到线上,把线上的服务流接进来,此后即可以做线上服务了。
由于我们有线上的完全自主研发的 online 数据库,可以实时地将这个特征给抽取出来,因此 OpenMLDB 解决的核心问题,就是保证线上线下特征计算一致性。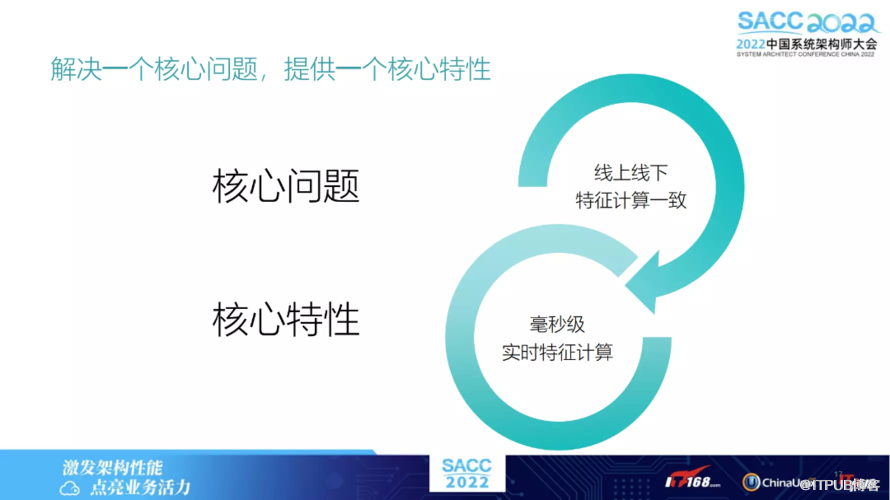
由于我们有公用统一的 SQL 的执行引擎,因此核心特性可以理解为在线上能够提供毫秒级的实时特征计算。OpenMLDB 的应用场景多种多样,若对离线训练和线上均有较高需求,可以两套引擎同时使用,以保证一个线上线下一致性。
当然也有些客户可能只是做一些离线的训练,离线训练可以使用离线引擎,如果只是关注比较低延迟的特征计算可以使用在线引擎,可以根据不同的应用场景做一些选择。
以下是 OpenMLDB 的一些开源生态,并在其中负责特征方面。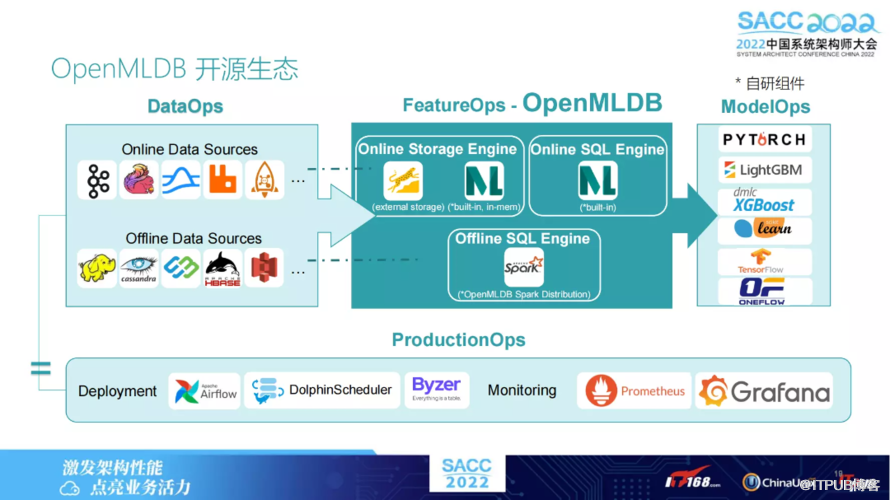
案例一:客户 Akulaku
以下是 OpenMLDB的一个客户,Akulaku。它是一个东南亚的金融公司,是最早使用OpenMLDB 开源版本的一个客户。其实在离线和在线上,特征数据库里都选择了 OpenMLDB。为它提供离线、在线特征数据库这两个功能。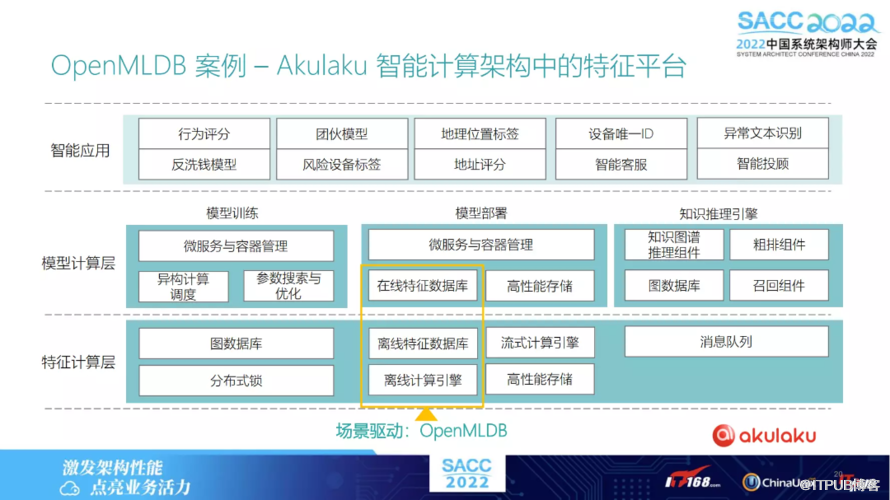
Akulaku找我们的时候,其实他们面临上述提到的一些技术挑战:
逻辑的一致性问题。线上训练、线下抽取特征,可能跟线上对不上。
对于线上他们需要低延迟,线下需要高吞吐,OpenMLDB 能够满足此需求。特征方面直接使用 SQL 的接口,通过 SQL 作为离线、在线的桥梁,以此满足在线和离线用完全一套代码去做特征抽取。

最后实现上,他们的的订单数据量,大概一天10亿条,部署 OpenMLDB 之后,将特征收益脚本进行线上 deploy 之后,可以达到测试结果大概为4毫秒的延迟,即可满足他们一个上线的一个需求。
案例二:客户 37手游
另一个客户是37手游,玩手游的同学可能知道这家公司,他们也是有些业务场景需要用到一些 learning 的预测,其中是用到用户流失的一个预测场景。
假设他们那个场景是在用户触发登录的时候就会去做预测,用户是否会在最近7天内流失,其中用到了 OpenMLDB 的集群板,做了一些三节点的部署,即可满足线上对于特征抽取的实时性的要求。
这大概是他们的SQL 设计。表的设计上有三张表:登录表、支付表、行为表。特征的话,他们会统计计算用户最近3天、7天、15天或一个月的登录次数,以及对应的支付金额,还有一些其他类的行为特征。
这些特征,都是通过OpenMLDB 的 SQL 脚本进行提取的。关于离线导出、在线服务的实验结论:
离线导出:快速对特征进行计算和处理;无需担心数据泄露等问题。
在线服务:一键部署,减少传统流程中关于新特征上线的开发工作量;上线周期从15/人/日调整为1.5/人/日。
上线的模式在很多公司比较常见,假设需要一个新的特征,首先我们可能会反馈给数据组,数据组会用一些程序写出来如何将特征提取出来,再进行一致性校验测试,期间需要花费很长时间。有了OpenMLDB之后,线下确认了这个特征确实是有效的。实则可以使用完全一样的一套程序,即可完成迅速上线。
高可用在线执行和存储引擎
以下介绍 OpenMLDB 中用到的一些技术点,即如何保证线上引擎的高可用、低延迟。下图右侧是我们线上引擎的一个架构,就是我们主要有三个模块: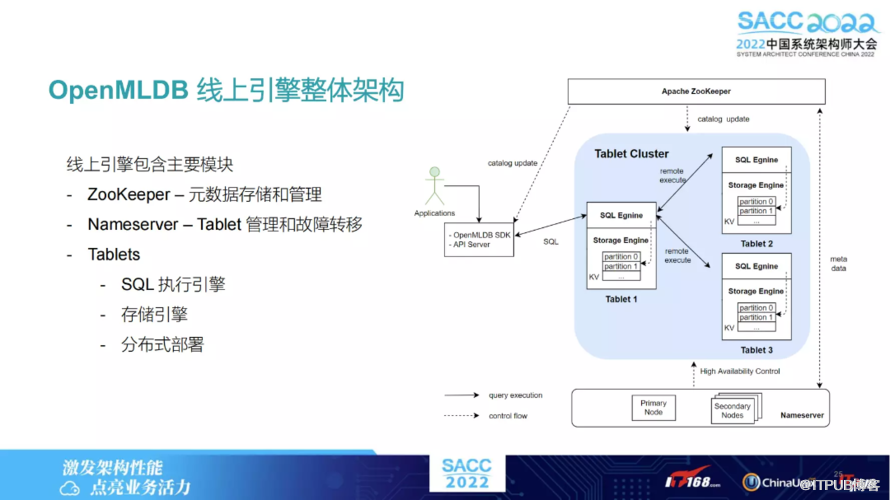
ZooKeeper,用来维护元数据的更新。
Nameserver,主要是为了数据节点“Tablets”的管理和故障转移。Tablets是存数据以及做 SQL 执行的核心模块,它也是多节点的模块。
Tablets,每个 Tablets 上面都会负责某一张表的部分分片;一个 SQL 也相当于进行分布式的执行。
假设这个 SQL 所需要的数据分布在不同节点上,便会在其中一个节点上做一些 Query Plan 的生成,然后某些节点会从其他节点上拿数据。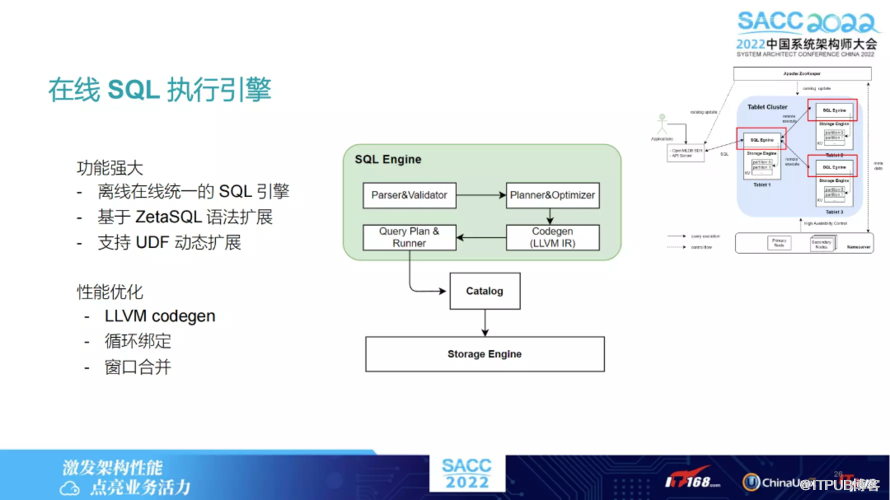
下图为在线引擎提供基于内存、外存两种存储引擎的选择:
基于内存:低延迟、高并发;较高使用成本提供毫秒级延迟响应。
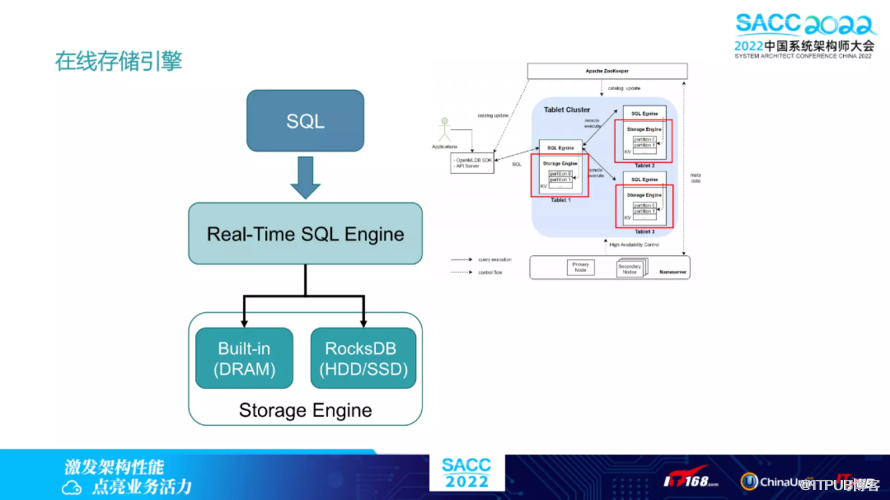
基于外存:对性能较不敏感;低成本使用落地基于 SSD 的典型配置下成本可下降 75% 基于RocksDB开发。
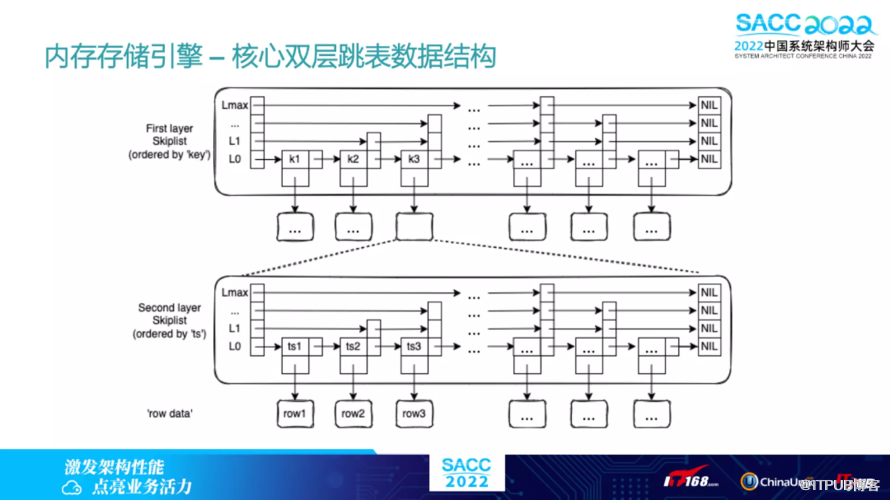
两种引擎上层业务代码无感知,零成本切换。另外,内存的存储引擎有个核心的数据结构,叫双层链表。双层链表内存索引结构如下:
第一层索引对应具体的键值,优化分组操作(如 GROUP BY);
第二层索引对应时间戳,高效找到时间窗口;
高效插入和查询,典型场景时间复杂度
高效支持数据过期(TTL)相关操作。
内存引擎也是自己设计的一套编解码格式,Header 之后,还有一个 BitMap,指的是某一列是否为空。如果是空的话,就不需要额外的存储空间去存这些域了。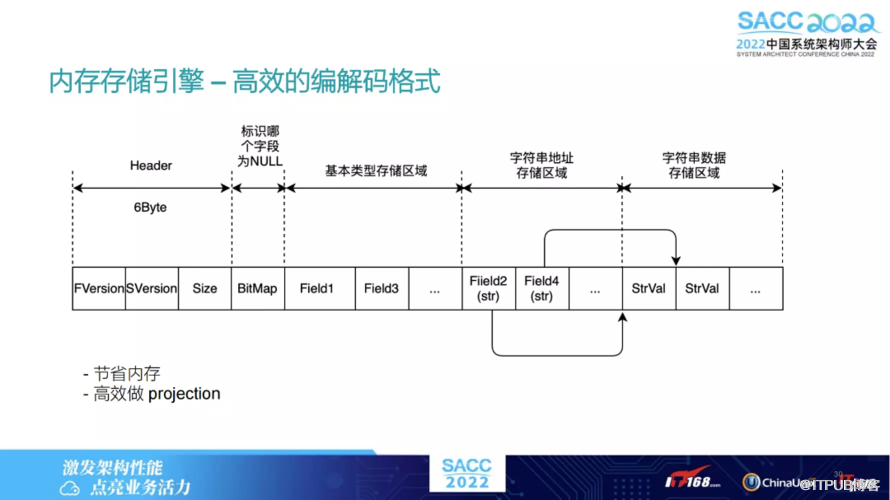
数据放在内存中,这涉及到如何保证数据的可恢复性,也即持久性。其中用到两个常用的技术,Snapshot 和 Binlog。
我们通过 SnapShot 方式将某一个内存状态存储到磁盘上。对 Binlog 来讲对于每一条更新数据,都可以通过此方式实时去更新。主动同步也是通过 Binlog 的方式,把最近更新的数据通过 此方式发送到其他节点上做同步。
上述讲到的主动同步,相当于是在一个集群上有不同的 Tablet 节点,下文将延伸讲解。假设我们需要双机房的容灾技术,该如何做?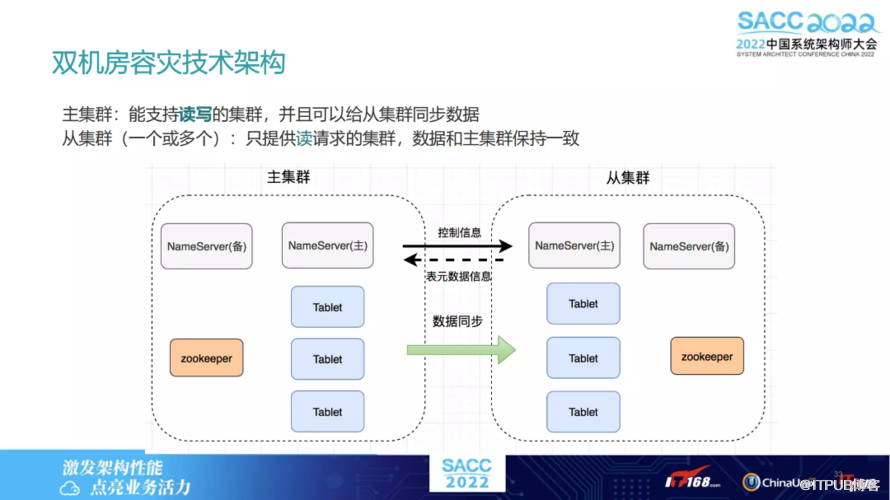
可能会涉及到多个集群,可能有主集群,有从集群这里面的一个同步,也是我们目前也是可以支持的,就是多双机房的一个容灾机制。
这里面涉及到两种同步信息:
控制信息,就是一个表源数据的信息;
数据同步信息。于主集群而言,相当于读写流量都会进到主集群里面。从集群只会接收读的流,它可以接受读的请求,同时会接收主集群过来的数据同步请求。
集群内部之间同步逻辑大概是类似的,也是通过 leader follow 的方式去同步从集群中某些分片,相当于是主集群的 follow。我们也是类似的模式,通过 leader 将数据通过 Binlog 形式传给 follower,然后 follower 再进行更新。
其中有一个预聚合技术,能够优化长窗口计算效率。如果时序窗口特征很大,假设是一年内数据,数据量很大,可能有几百万条,这时如何做到线上快速地实时计算。这就需要用到预聚合技术,相当于如果当数据插入的时候,会把数据提前做一些预聚合。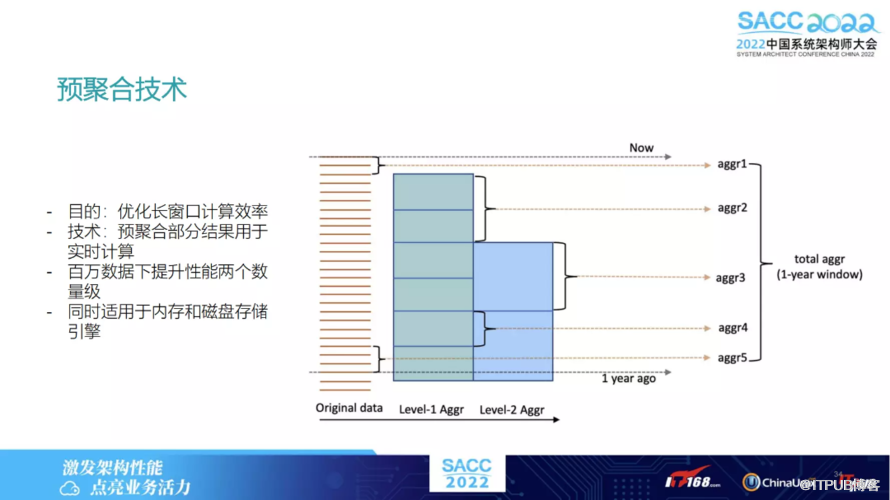
下图列出的是在线引擎的性能测试,展示的是实际窗口大小的情况下延迟和吞吐的情况。从延迟上看大概都应该是在20秒以内,在窗口达到10 K 左右时,也在20毫秒以内。其实延迟是大部分我们客户的一个需求,需要保证20毫秒以内。
另外下图中左右两侧的图片展示的是:对于不同的数据量Latency 是如何对延迟加以影响的。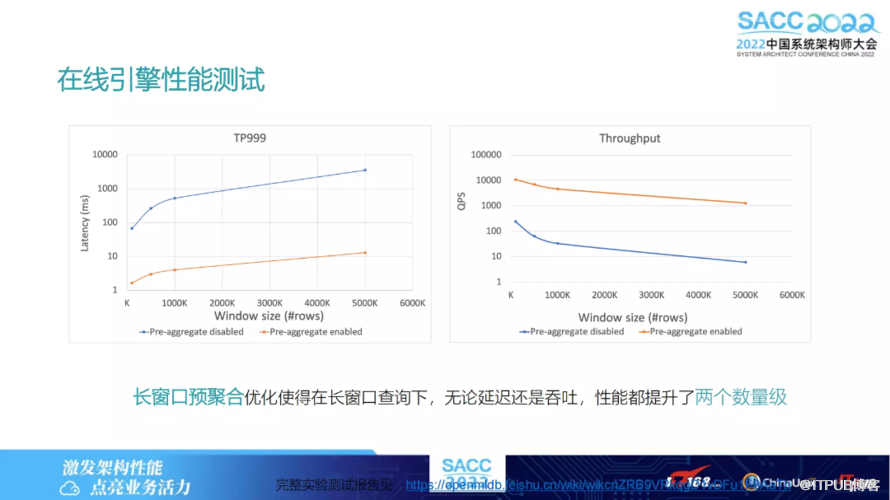
可以看到,数据量的不同对延迟几乎无影响。可以回忆一下我们有双层链表结构,传统跳表结构下可以以 log N 的时间复杂度找到对应的那个窗口数据,所以对延迟和吞吐几乎无影响。
以上两张图所呈现的是预聚合技术对性能的影响。黄色部分是我们有预聚合技术的效果,蓝色的是没有预聚合技术,也即这个窗口可能要更大一些相比于上图中的,比方就是百万千万的级别时,延迟可能就在秒级别了。有预聚合的话,可以看到这张图其实也在20毫秒以内了,吞吐也相应提升了两个数量级。
发展历程与未来规划
2021年6月份OpenMLDB 开源,发布了0.1版本;2022年8月份发布了0.6版本,10月中下旬发布的0.0.64版本。
开源之后,已有一些使用开源版本的客户,比如Akulaku、37手游、华为、京东科技。
目前在准备0.7.0版本,主要想提高SQL 能力,SQL 能够支持更多的功能,同时在稳定性、易用性上,会做更进一步的提升。

