阿里云发布通义千问2.0,性能超GPT-3.5,加速追赶GPT-4
10月31日,阿里云正式发布千亿级参数大模型通义千问2.0。在10个权威测评中,通义千问2.0综合性能超过GPT-3.5,正在加速追赶GPT-4。当天,通义千问APP在各大手机应用市场正式上线,所有人都可通过APP直接体验最新模型能力。
过去6个月,通义千问2.0在性能上取得巨大飞跃,相比4月发布的1.0版本,通义千问2.0在复杂指令理解、文学创作、通用数学、知识记忆、幻觉抵御等能力上均有显著提升。目前,通义千问的综合性能已经超过GPT-3.5,加速追赶GPT-4。
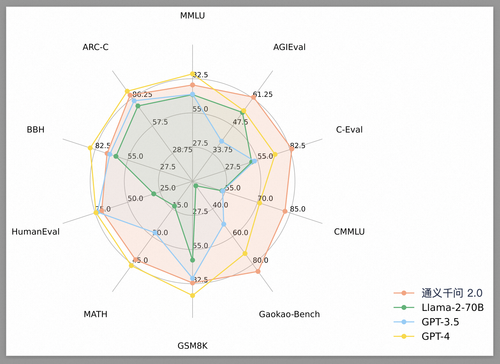
图:通义千问2.0综合性能超过GPT-3.5,正在加速追赶GPT-4
在MMLU、C-Eval、GSM8K、HumanEval、MATH等10个主流Benchmark测评集上,通义千问2.0的得分整体超越Meta的Llama-2-70B,相比OpenAI的Chat-3.5是九胜一负,相比GPT-4则是四胜六负,与GPT-4的差距进一步缩小。
中英文理解能力是大语言模型的基本功。英语任务方面,通义千问2.0在MMLU基准的得分是82.5,仅次于GPT-4,通过大幅增加参数量,通义千问2.0能更好地理解和处理复杂的语言结构和概念;中文任务方面,通义千问2.0以明显优势在C-Eval基准获得最高得分,这是由于模型在训练中学习了更多中文语料,进一步强化了中文理解和表达能力。
在数学推理、代码理解等领域,通义千问2.0进步明显。在推理基准测试GSM8K中,通义千问排名第二,展示了强大的计算和逻辑推理能力;在HumanEval测试中,通义千问得分紧跟GPT-4和GPT-3.5,该测试主要衡量大模型理解和执行代码片段的能力,这一能力是大模型应用于编程辅助、自动代码修复等场景的基础。

图:通义千问2.0发布
通义千问更成熟了,也更好用了。通义千问2.0在指令遵循、工具使用、精细化创作等方面作了技术优化,能够更好地被下游应用场景集成。通义大模型官网上线了多模态和插件功能,支持图片输入、文档解析等细分任务。
与此同时,基于通义大模型训练的8大行业模型组团上线,他们分别是通义灵码-智能编码助手、通义智文-AI阅读助手、通义听悟-工作学习AI助手、通义星尘-个性化角色创作平台、通义点金-智能投研助手、通义晓蜜-智能客服、通义仁心-个人专属健康助手、通义法睿-AI法律顾问。8大行业模型面向当下最受欢迎的多个垂直场景,使用领域数据进行专门训练。用户可以在官网直接体验模型功能,开发者可以通过网页嵌入、API/SDK调用等方式,将模型能力集成到自己的大模型应用和服务中。
图:通义大模型家族全面升级,8大行业模型组团上线
截至10月,阿里云已与60多个行业头部伙伴进行深度合作,推动通义千问在办公、文旅、电力、政务、医保、交通、制造、金融、软件开发等领域的落地。
周靖人透露,阿里云计划近期开源通义千问72B版本,此前,阿里云已先后开源7B和14B版本模型,模型累计下载量超过100万。阿里云将持续支持千行百业的开发者基于通义千问开源模型进行模型和应用创新。

图:通义千问72B即将开源

