AMD持续发力GPU:压力给到了英伟达
如果说世界上有哪个市场迫切需要激烈竞争,自然就是推动AI革命的数据中心GPU市场。目前英伟达几乎就是行业内唯一的神。

随着时间推移,AMD的Instinct GPU加速器也变得越来越具有竞争力。随着此番推出的Instinct MI325X和MI355X,AMD已经能够在GPU层面与英伟达的“Hopper”H200和“Blackwell”B100相抗衡。
但AMD自己也很清楚,在消费者采购的互连与系统软件、AI框架以及GPU加速器当中,英伟达在诸多层面仍然掌握着决定性优势。可话又说回来,既然很多企业压根就买不到英伟达的GPU,那么转而选择AMD的GPU产品总要比在生成式AI执法当中袖手旁观要好得多。此外,AMD也正在利用其ROCm技术栈追赶CUDA,并希望能与其UALink合作伙伴共同开发出一套统一的内存互连,用以与英伟达专有的NVLink和NVSwitch架构展开竞争,从而构建起机架规模甚至是行规模系统。
而在此番于旧金山召开的Advancing AI大会上,关于MI325X以及MI355X更多细节的揭晓以及对未来MI400的暗示,也成为业界广泛关注和讨论的话题。每个人都期待AMD能够拿出混合精度更广、HBM内存容量和带宽更大的GPU加速器产品。
下面我们就从MI325X开始,看看其速度与数据馈送指标与今年6月在中国台湾Computex展会上展示的情况相比有何变化。
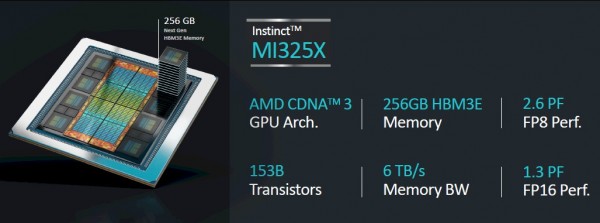
通过上图所示的速率表可以看到,MI325X复合体拥有1530亿个晶体管,这样的晶体管封装规模可谓相当庞大。FP16半精度下1307.4万亿次的浮点数学性能和FP8四分之一精度下2614.9千万亿次的浮点数学性能与四个月前的宣传完全一致。但是,MI325X的内存容量略低于预期。最初,AMD表示预计这八个HBM3E内存栈的总容量为288 GB,但出于某些原因(可能是受到12层3 GB内存栈的产能限制),其实际容量只有256 GB。内存带宽倒是与6月的公布结果一致,即8个HBM3E技术栈共提供6 TB/秒传输整训工。
MI325X具有与现有“Antares”MI300X GPU相同的性能。更具体地讲,MI325属于同样的计算复合体,沿用台积电公司相同的4纳米制程工艺制造而成,只是功率从750瓦提升到了1000瓦,因此能够带动更大的HBM内存容量和更高的传输带宽。
MI300X拥有192 GB大小且速度略慢的HBM3内存,其封装内的总传输带宽为5.3 TB/秒。据我们了解,两款产品在GPU块和HBM3/HBM3E内存之间的256 MB Infinity Cache缓存也是完全相同的。
MI325X可以接入与MI300X相同的插槽和同样的Open Compute通用基板服务器平台,因此无需创建新的服务器设计来容纳这些新款GPU加速器。当然,用户必须拥有充足的热容量对其进行冷却。
下面来看使用MI325X的八路GPU节点的馈送与速度指标:
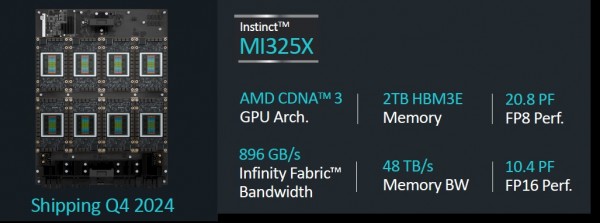
每个MI300系列GPU都拥有7条128 GB/秒的Infinity Fabric链路,这使其能够在节点之内以全对全的形式共享内存配置连接。
AMD公司CEO苏姿丰在会上表示,MI325X将在本季度末开始出货,并将在明年第一季度登陆合作伙伴产品。而就在同一时间点,英伟达应该也将腾出手来交付更多Blackwell B100 GPU产能。
但目前来看,AMD仍满足于将MI325X与大内存版Hopper H200 GPU进行比较,后者在其六个堆栈中配备有141 GB的HBM3E内存和4.8 TB/秒的传输带宽。相比之下,AMD在GPU内存容量方面具有1.8倍的优势,意味着加载特定模型参数所需要的GPU数量只相当于英伟达的1/1.8,而传输带宽方面则具有1.25倍的优势,因此能够缩短将参数信息提交给GPU所需要的时间。(其实测试内存容量及带宽对于AI训练性能的影响非常有趣,我们将在后续文章中尝试探究其中的真相。)
以下是苏姿丰在大会上展示的基准测试结果,对比双方分别为MI325X与英伟达H200:
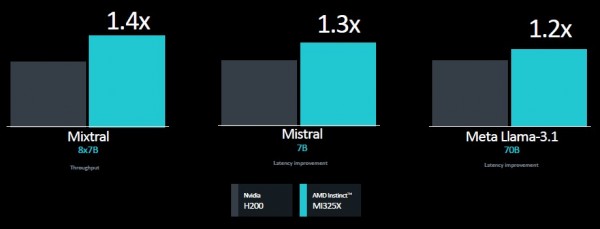
在这三项推理测试中,性能似乎主要由MI325X和H200之间的带宽差异决定,而且具体结果还存在一些波动。上图左侧所示的Mixtral基准测试衡量的是推理吞吐量,因此其中内存容量似乎有着更为重要的影响;而中间Mistral和右侧Llama 3.1测试衡量的则是推理延迟,这似乎主要由HBM传输带宽决定。
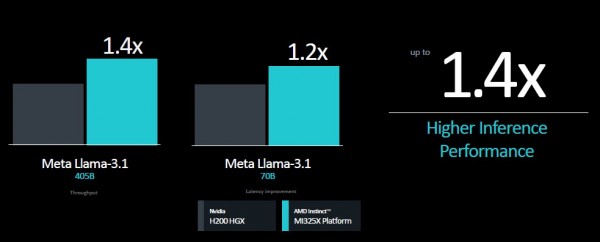
在八路GPU平台之上,以上优势也都将被等比例放大:

下图所示为Llama 3.1基准测试中的部分性能规格,其中分别选取70B和405B两种参数规模来证明1.4倍的性能优势结论:
我们一直希望能看到关于AI训练的基准结果,而AMD此番也终于带给我们两个数据点,这里使用的是Meta Platforms的旧版Llama 2模型:

在我们看来,最有趣的就是在使用单个设备时,MI325X的性能要比H200高出10%;但在转向八路GPU节点时,这种优势则会消失。我们猜测跟英伟达HGX设备中使用的NVSwitch互连相比,Infinity Fabric的速度还不够快,因此抵消了性能优势。但在性能相当的情况下,可能NVSwithc和H200 HGX复合体当中使用的那些“粗大”的900 GB/秒NVLink通道也并没有我们想象中那么效果拔群。至少在Llama 2推理场景下看是如此。
可是AMD老兄,Llama 3.1训练数据在哪里?这才是当下大家最关心的。
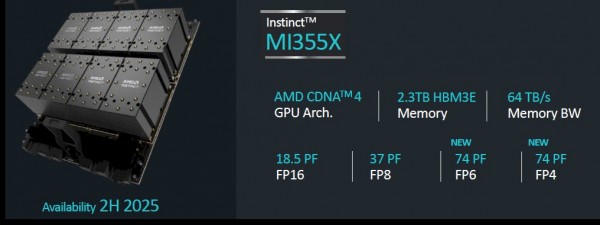
接下来,让我们转向Instinct MI350系列GPU。作为AMD旗下新的产品家族,此番打头阵的正是MI355X。
MI350系列将采用CDNA 4架构,据推测是从预计于2026年推出的再下一代MI400系列数据中心GPU中借鉴而来。MI350系列将采用台积电的3纳米制程工艺,而且大概率会在插槽中安装八块芯片(因为除非在反面也部署chiplets小芯片组,否则整张卡也太高太薄了)。
正如今年6月所透露,MI350系列将是AMD首款支持FP4和FP6浮点数据格式的GPU。它们将拥有完整的288 GB HBM3E内存,采用12层的3 GB堆栈。按照8个堆栈计算,那么其将为HBM3E内存提供8 TB/秒的传输带宽。
无论CDNA 4架构如何,MI355X插槽都将提供1.8倍于MI325X的性能表现,即在FP16精度下为2.3千万亿次,在FP8精度下为4.6千万亿次,在FP6或FP4精度下则为9.2千万亿次。(这还不算稀疏矩阵支持,如果大家的负载不涉及对密集矩阵的数学运算,那么吞吐量还可以再提高一倍。)
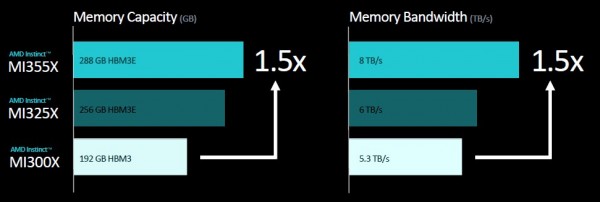
这就引出了另一个问题:相较于MI325X,MI355X是否会内存不足。如果说MI325X已经在计算和内存比率方面达到平衡,分别为288 GB和6 TB/秒,那么我们预计MI355X将拥有512 GB的HBM3E内存容量和14.4 TB/秒的内存带宽。如果情况真是如此,那么相信大家也会认同这是一款相当强大的GPU加速器。
总而言之,下面来看八路MI355X系统板的馈送能力与速度表现:
下图所示,为MI300X、MI325X和MI355X之上八路系统板的性能范围与能够处理的参数规模:
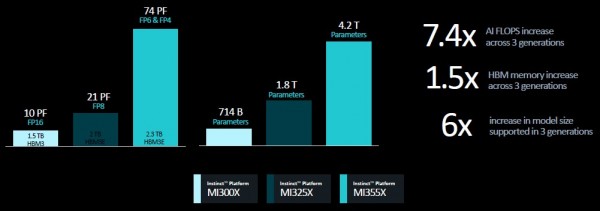
曾几何时,5000亿参数就足以令人目眩;但现在看来,似乎几十万亿也变得没什么大不了的。
我们期待看到MI400系列中使用的CDNA-Next架构会是什么样子,也好奇AMD未来会用什么样的封装将更多东西疯狂塞进插槽。另外我们还将关注AMD如何进行下一步产能规划,并逐渐从英伟达手中抢夺更多市场份额。至少就目前来看,只要HBM的供应量充足,一切就皆有可能。
原文链接:https://www.nextplatform.com/2024/10/10/amd-gives-nvidia-some-serious-heat-in-gpu-compute/

