如何为数百万用户构建可扩展性系统?
你可能知晓,在大型科技公司计划为数百万用户提供服务时,系统的可扩展性能力通常需要从一开始就成为设计的一部分,而不应在后期被追加。否则,随着用户期望的不断攀升和全球流量模式的变化,该系统将根本无法应对。下面,我将向你介绍大型科技公司通常会如何看待大规模的可扩展性,他们在现实世界中的有效策略(不仅仅是理论),以及可用性、成本、可观察性是如何在系统设计中被结合到一起的。
可扩展性为何重要?
一个庞大的系统,不可避免地会面临硬件失效、网络问题、甚至是数据中心瘫痪等潜在威胁。对此,人们通常的做法是:
将系统分解为单独的部分,以便某个故障不会拖累其他部分
不仅需要备份服务器,也应备份数据库、存储库、甚至是整个地理区域的系统
持续执行运行状况检查,并设置自动故障转移,以实现无需人工干预的恢复
根据实时需求扩展或缩减系统资源
密切监视系统行为,以便在其出现重大中断之前,捕获早期警告信号
当然,上述做法并非一劳永逸之事。运维团队需要持续根据真实情况和经验教训,不断改进系统的可扩展性。
跨区域扩展系统
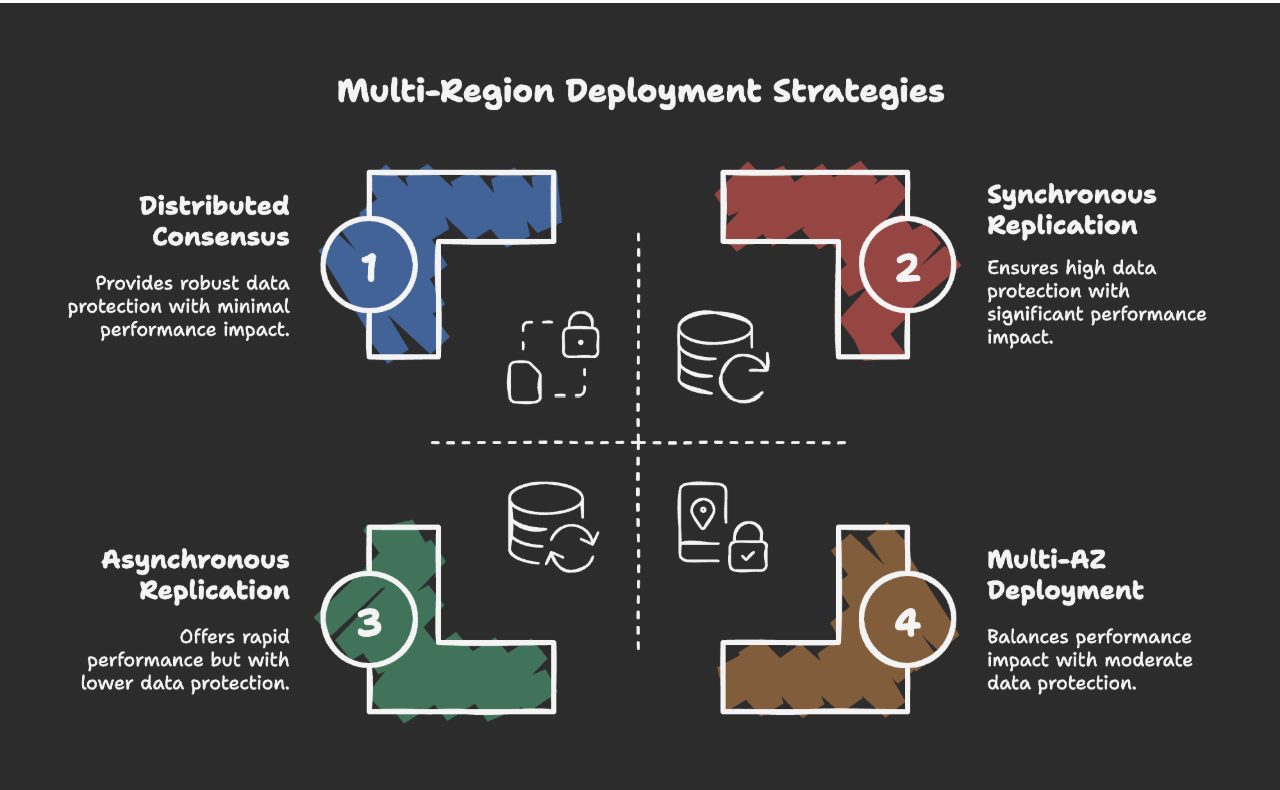
多区域部署策略
提高可扩展性的一项明智举措是将系统分布在不同区域。AWS 和 GCP 等平台就是这样构建的。由于它们在不同区域被设计为相互隔离,因此每个区域都可以独立的方式运行,即使有整个区域系统出现离线的状况,其他区域的系统也能够继续运行。而且,该区域的用户也会被自动路由到运行状况良好的区域,进而让用户甚至不会注意到本区域的系统出现了故障。
目前,科技公司通常采取两种方法来实现数据的跨区域复制:
异步复制:虽然效率更高,但是一旦灾难在关键时间点发生,用户可能会丢失一些最新尚未完成同步的数据。
同步复制:对于关键数据来说更安全,但是势必会引入一些因前一项同步未完成,而造成的延迟。
大多数实际架构最终都会将两种方法混合在一起。也就是说,具体该如何设置,往往取决于系统的哪些部分可以承受哪一类的风险。
前文提到了区域隔离。其实,并非每个系统都需要多区域的设置。业界也有公司将多个可用部分部署在单个区域内,以处理大量数据。对于那些关键性的服务和任务、以及面对非常严格的合规性要求时(如“两地三中心”),多区域设计仍然是非常必要的。
设置正确的故障转移计划
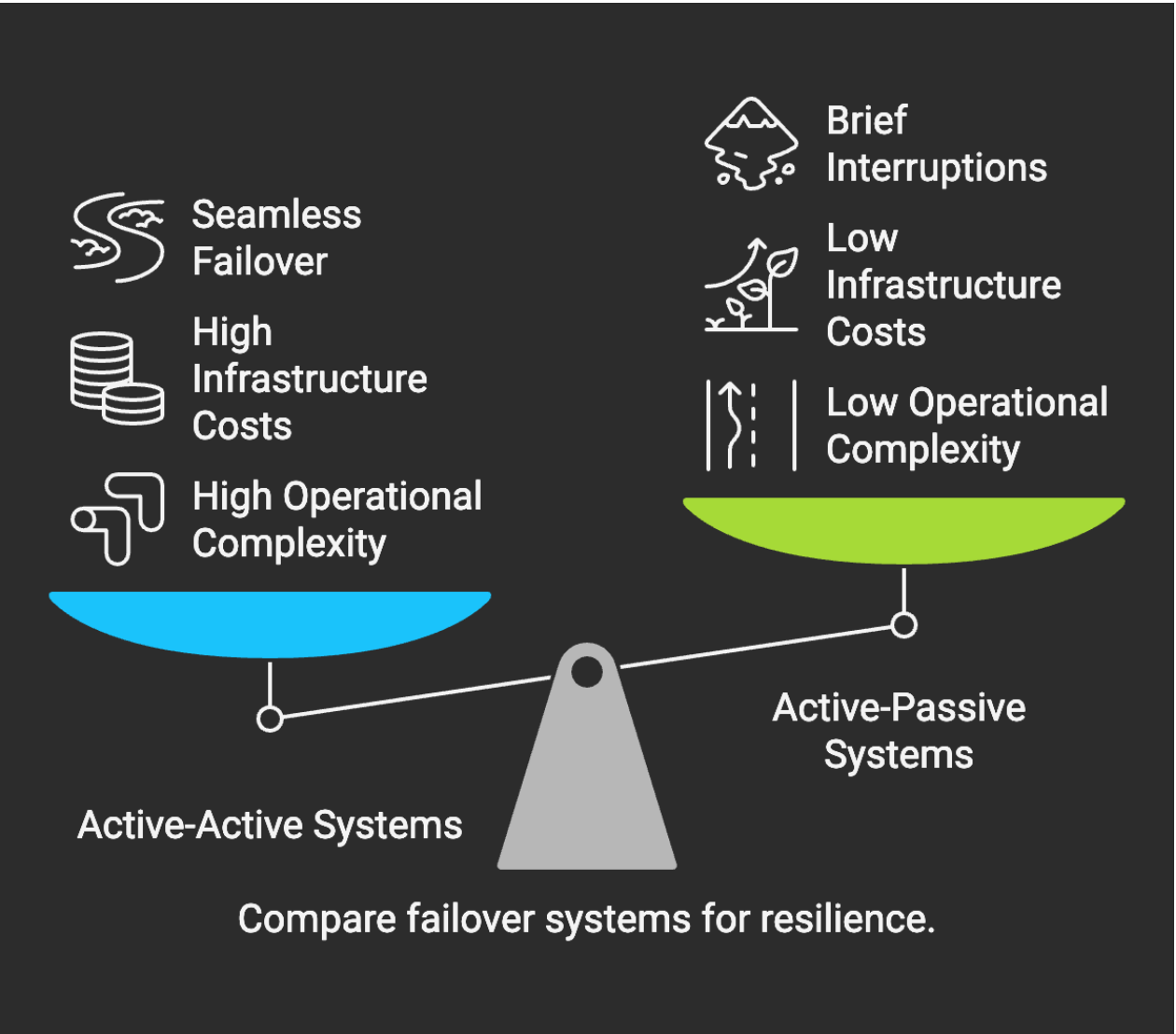
设置正确的故障转移计划
每个可扩展的系统都需要有可靠的故障转移策略作为支撑。通常,我们有两种转移模型可供选择:
主+主设置:是让多个节点或区域同时处理实时流量。如果一个节点出现故障,另一个节点会立即接手。该模型几乎为系统提供了零停机时间,不过需要团队非常小心地维持同步和平衡。
主+被设置:让一个活跃节点执行所有工作,而另一个备用节点则处于空闲状态,等待故障。该模型更简单、更便宜,但在切换期间可能会出现短暂的中断。
无论你选择哪种模型,定期的故障转移测试都是必须的,毕竟模拟失败和恢复演练是大型系统运维团队必须具备的基本能力。
使用自动扩展为流量峰值做准备
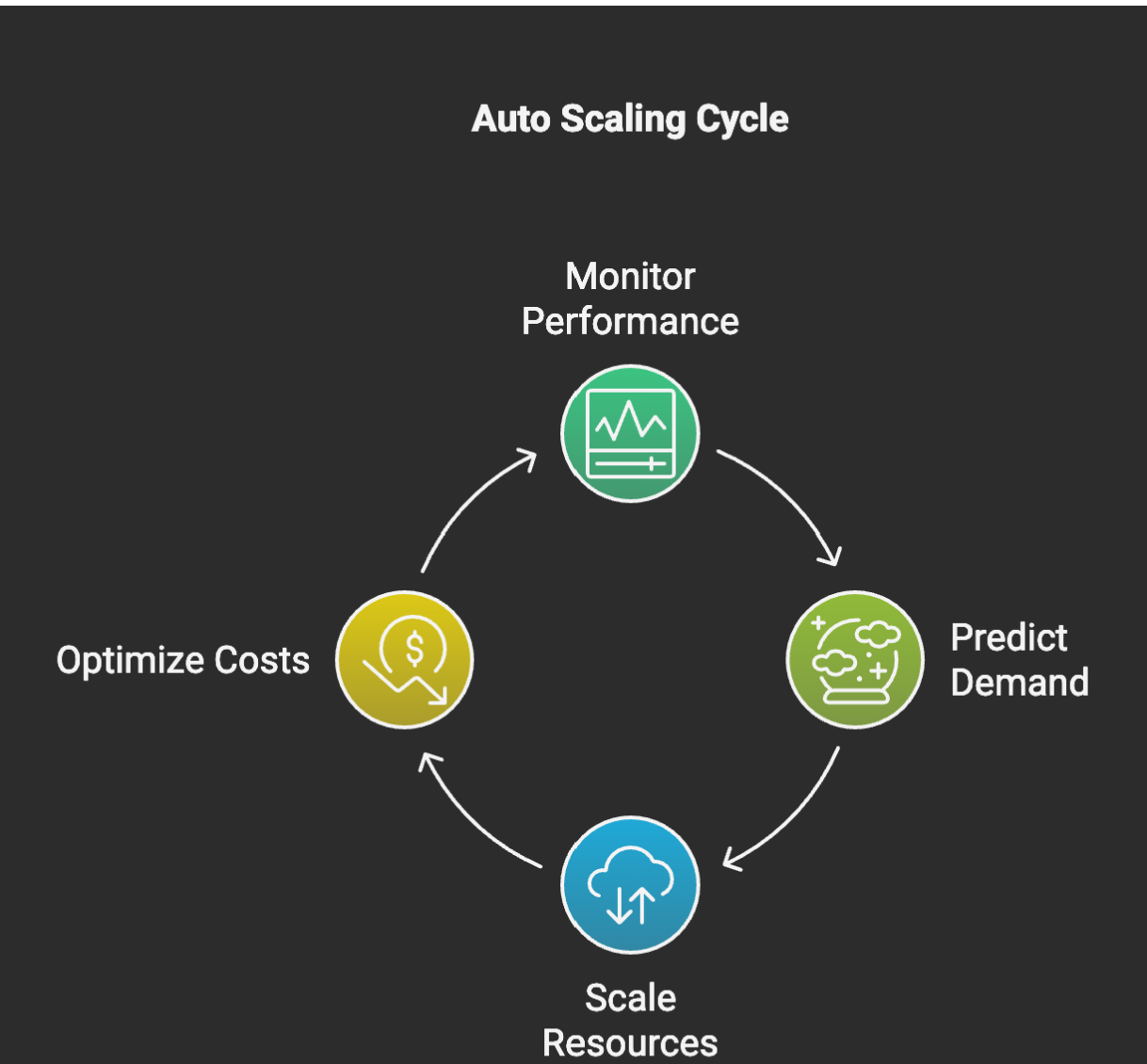
如果你的系统无法随流量的变化进行自动调节,那么请求峰值一旦出现,系统就可能出现大量延时甚至中断。这也就是需要引入自动扩展(Auto Scaling)工具的必要所在。此类工具允许你的系统能够根据实时使用情况的特征数据(如 CPU 负载、内存使用情况或请求数量),自动添加或删除资源。在此基础上,预测性的自动扩展工具可以根据历史模式,预测需求高峰的到来,例如,在黑色星期五大促开始之前提前扩容。
当然,扩展需要在整个技术栈中进行,并涉及:Web 服务器、数据库、缓存、消息队列等任何可能造成瓶颈的薄弱环节。
值得注意的是:自动扩展策略需要经过测试与验证,以调整好智能阈值、冷却期和开销监控。否则,你最终可能会既浪费资源,又推高成本,还未实现预期的效果。
微服务:通过分解来处理故障
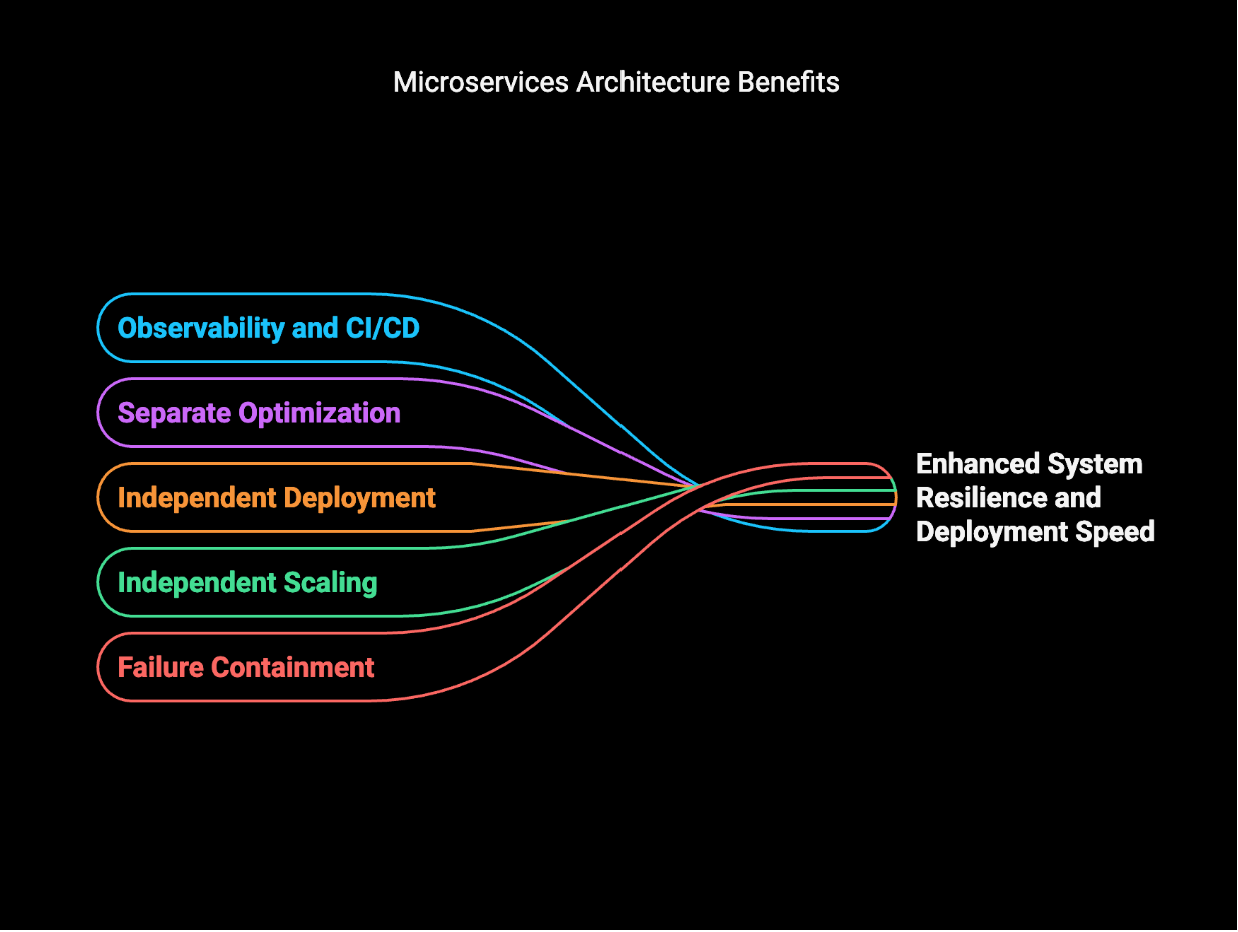
微服务架构的优势
目前,微服务已成为构建具有可扩展能力的大规模系统的首选架构。其基本思想是将一个大的系统拆分成许多较小的、集中的服务。而且这些服务能够通过 API 来相互通信。因此,该方法带来了如下好处:
如果有一项服务失效,其损害会得到控制,而不会导致整个系统的瘫痪。
每一项服务都可以根据自己的需求进行独立扩展。
运维团队可以只更新部分服务,而不会影响到系统中不相关的部分。
各项服务可以分别使用适合其自身需求的更优技术。
当然,微服务也带来了一定的复杂性。运维团队需要管理诸如:服务发现、分布式跟踪、集中式日志记录、以及更复杂的部署管道等方面。
虽然微服务并非免费,但是如果你的目标是在大型系统中实现可扩展性、以及快速迭代的话,此类技术仍然值得大规模采用。
可观察性:获悉系统是否正常运行
在复杂的系统中,可观察性往往可以从如下三个方面,让你领先于问题的恶化,了解其根本原因:
通过各项指标的展示,为你提供有关错误率、延迟、吞吐量和资源使用情况等方面的数据。
通过日志记录整个系统中的事件,以便你可以在出现问题时进行调查。
通过分布式跟踪允许你跨多个服务跟踪单个请求,以查找和定位瓶颈或故障点。
为了达到上述三个方面的可观察性,运维团队通常需要使用诸如: AWS CloudWatch、X-Ray 等平台,以及 Prometheus 和 Jaeger 等开源工具,给系统和应用构建控制面板、综合检测、主动运行状况监控、以及警报服务。
真正关键的不在于工具,而是确保系统从一开始就本着易于观察和故障排除的初衷予以搭建。可见,良好的可观察性不但可以为运营团队缩短事件的发现时间,易于找到根本原因,而且能够协助团队在故障真正影响到用户之前,被及时修复。
管理三平衡:成本、速度和可扩展性
成本、速度和可扩展性
在实践中,构建可扩展的系统往往需要从如下三个方面做出权衡与取舍:
强一致性虽然可以为你提供更安全的数据保障,但是可能会降低系统的运行效率。
高可用性架构的基础设施往往成本更高,但是能够为你避免更大的停机损失。
复杂的设计虽然可以为你提供强大的可扩展性,但是可能会让后期维护遇到困难。
对于不同规模和重要程度的系统而言,有时候,大型科研公司必须投入大量的资金,以避免哪怕一分钟的停机时间。不过,再有钱的公司也无法做到360度无死角的高可用性,因此他们需要根据系统中的数据价值,通过模拟故障,对停机可能对业务造成的影响进行建模,并运行混沌测试的方式,发现真正的弱点,以最终做出深思熟虑的取舍。
小结
综上所述,对于大型科技公司而言,在全球范围内构建可靠的系统是一项艰巨的工作。它往往需要仔细的规划、深思熟虑的权衡、时刻保持警惕,以及致力于从每一次故障中吸取教训。因此,系统构建者应该将可扩展性视为一个持续改进系统容错能力、提供出色的用户体验的过程,而不是一次性的项目。下面四点建议希望能给构建者们起到提醒作用:
可扩展性应在架构设计期间考虑,而不是在后期被追加。
每次事件发生后,各个团队应开展无指责的复盘,并专注于改进与提升。
系统变更需谨慎,通常可以参照金丝雀(Canary)等部署策略一起推出。
混沌工程可以被用于主动测试系统在大量请求压力下的行为状况。
就可扩展性本身而言,我们并没有放之四海而皆准的答案。其构建程度完全取决于你的用户、你的业务、以及那些你绝对无法承受的中断类型。
原文链接:https://dzone.com/articles/resilient-systems-for-millions-tech-architecture

