在第16届中国数据库技术大会(DTCC2025)大会上,ClickHouse Inc技术总监王鹏程,根据自己和团队在ClickHouse的技术实践经历,发表了题为《ClickHouse在AI领域的进展和应用》的主题演讲,分享了ClickHouse在现代数据架构中的创新应用,特别是在向量搜索、智能代理分析、机器学习数据管理等关键领域的突破。本文由ITPUB整理,经王鹏程老师授权发布。以下为演讲实录。
技术革新与生态扩展:从高性能分析到统一数据平台
ClickHouse的发展历程始于2009年,当时第一个原型(prototype)正式完成。在随后的多年中,ClickHouse逐步演进,但始终以一个“纯野生”的开源项目形态存在,吸引了超过1500名贡献者(contributors)——这个数字在开源项目中非常罕见,也充分体现了其社区活力和项目成熟度。
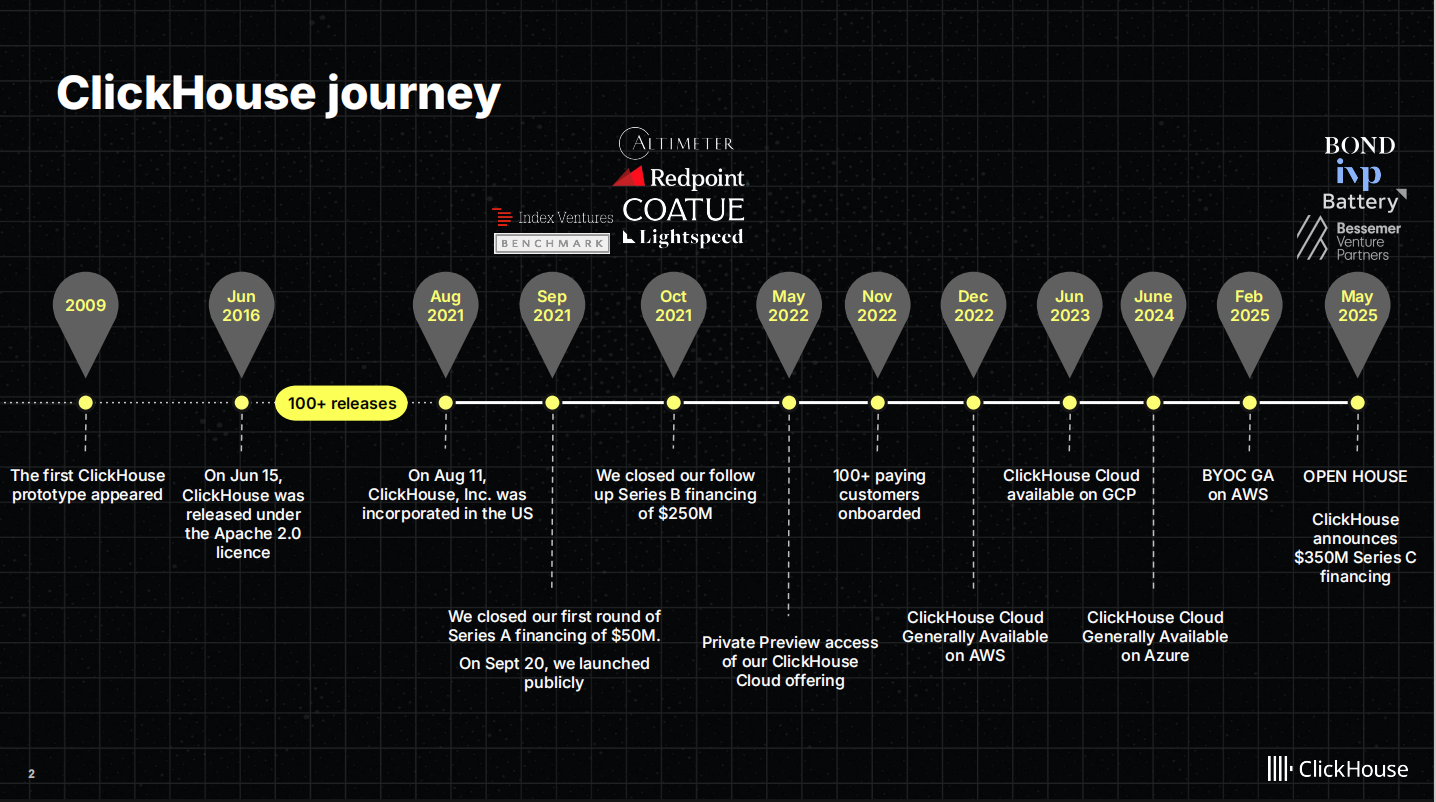
直到2021年,ClickHouse Inc公司正式成立,标志着项目从社区主导走向商业化的重要转折。在此之前,ClickHouse完全依靠开源社区推动,积累了强大的技术底蕴和用户基础。公司成立后,我们开始提供正式的SaaS服务,初期主要聚焦海外市场。值得一提的是,ClickHouse本身是一家美国公司,因此“出海”对我们而言更像是回归本土市场。目前,我们也在中国积极拓展,并与阿里巴巴合作推进ClickHouse Cloud服务。此外,ClickHouse Cloud已在海外三大云平台(AWS、GCP、Azure)全面上线。
在融资方面,截至2025年5月,我们完成了3.5亿美元的融资,公司估值达到约63.5亿美元,这也成为ClickHouse发展历程中的一个重要里程碑。

近年来,数据库领域呈现出一个显著趋势:用户不再满足于单一功能的数据库,而是希望将数据统一存储,并通过一个平台进行多种类型数据的查询和分析。ClickHouse积极响应这一趋势。在JSON支持上进行了彻底的重构,不再是简单的文本处理,而是动态地为JSON的键创建索引,使其查询性能堪比关系型列式存储,这也让我们在知名的JSONBench基准测试中取得了领先的成绩。
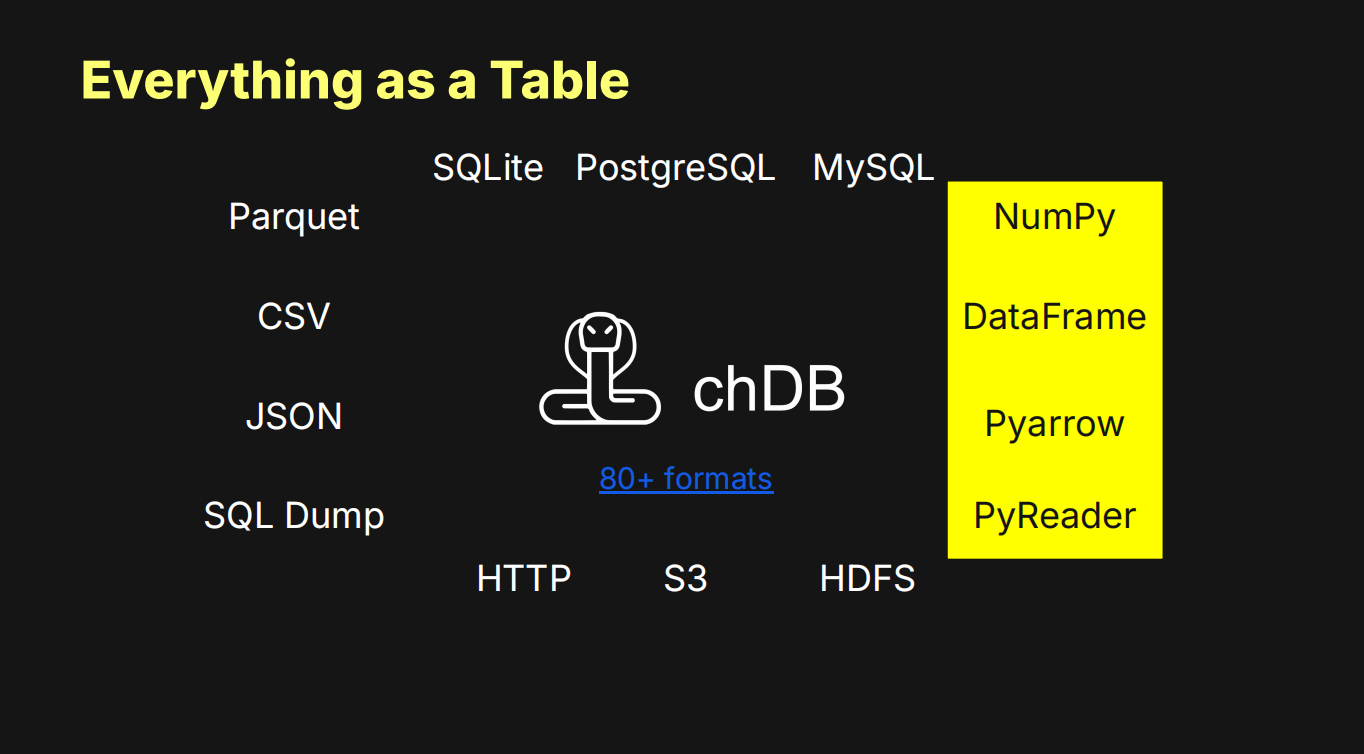
此外,ClickHouse的强大之处在于其“万物皆可为表”的生态能力。在湖仓一体的趋势之下支持包括Iceberg、DeltaLake、Hudi在内的多种开放表格式,并能直接查询存储在S3、HDFS、甚至本地文件系统上的各种格式(如Parquet、CSV)的数据,无需预先导入。为了进一步降低使用门槛,我做了一个名为“chDB”的开源项目——一个嵌入式的ClickHouse引擎。用户无需安装部署,chDB可以作为Python的一个模块import引入,无缝使用,不需要安装任何依赖,可以直接python中通过chDB查询文件乃至pandas的DataFrame。据测算,chDB的速度比pandas要快60多倍,这为数据科学家进行数据探索和准备提供了极大的便利。
ClickHouse Cloud:云原生架构与全球扩展
作为ClickHouse公司的主要营收业务,ClickHouse Cloud代表了我们从开源项目向企业级云服务迈进的关键一步,开源和云计算二者是一个互相推进的模式。尽管ClickHouse起源于开源社区,但通过云服务的形式,我们正在全球范围内推动高性能数据分析的普及。除非遇到像特斯拉这样极具规模且坚持私有化部署的超大型客户,我们通常以SaaS模式提供服务,这也使我们能更专注于产品迭代与用户体验的提升。

ClickHouse作为一家美国的公司,自诞生之初就深刻理解全球市场对安全与合规的严苛要求。ClickHouse Cloud已通过了包括SOC2TypeII、ISO27001、GDPR、HIPAA等在内的多项权威认证。这些认证并非一纸空文,而是贯穿于我们产品设计、开发流程、基础设施运维和数据处理全生命周期的严格实践。这意味着,无论是金融、医疗还是物联网领域的企业,在面向全球用户、处理敏感数据时,ClickHouse Cloud都能提供从物理安全到数据隐私的全面保障,为客户业务出海扫清合规障碍。
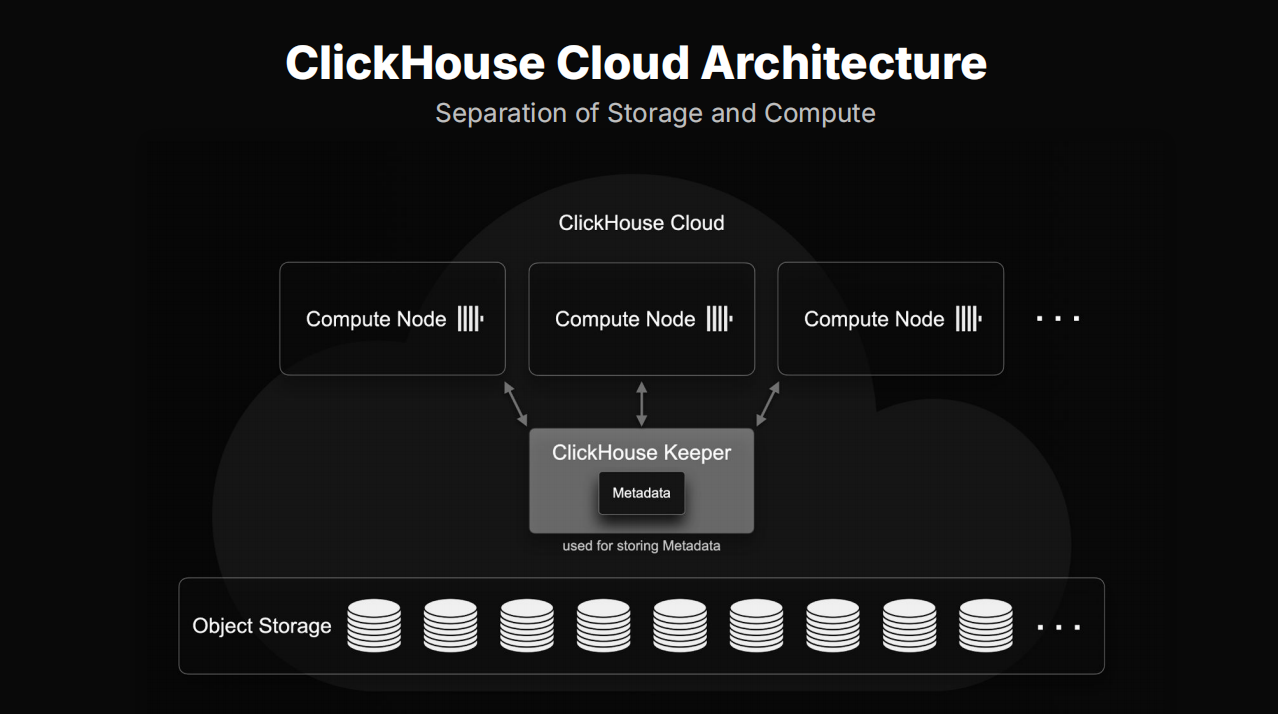
ClickHouse Cloud与开源版本最大的区别在于其存算分离的架构设计。起初,作为一个崇尚性能极致的数据库系统,存算分离似乎与“数据离计算越近越好”的直觉相悖。然而,基于AWS S3等高吞吐、低延迟的对象存储技术,存算分离不仅成为可能,还带来了显著的弹性与成本优势。ClickHouse Cloud将数据统一存储在对象存储中,通过元数据服务器(MetadataServer)和多个计算节点(ComputeNodes)实现高效查询,用户几乎感知不到数据位置带来的延迟。
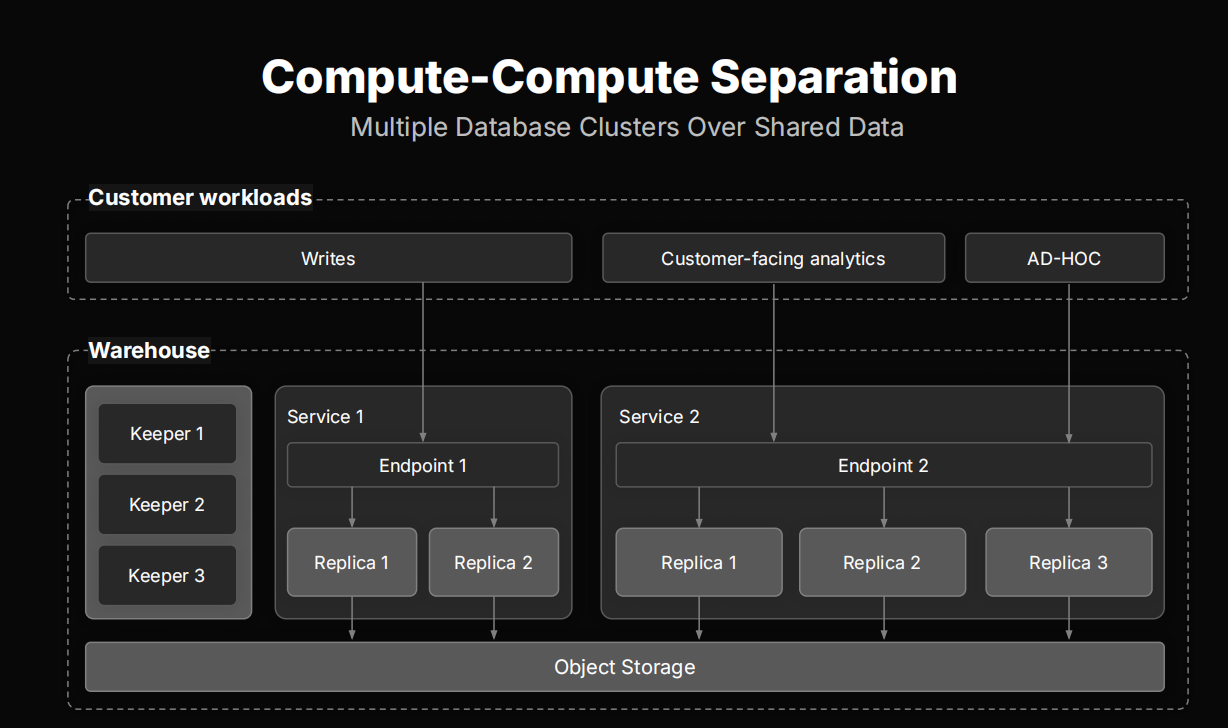
更进一步,我们还实现了“计算-计算分离”(Compute-Compute Separation),将不同类型的负载——如写入合并(Merge)、即席查询(AD-HOC)和面向客户的查询(Customer-facing)——分别调度至不同的服务节点,确保各类任务互不干扰,保障系统整体的稳定与高性能。
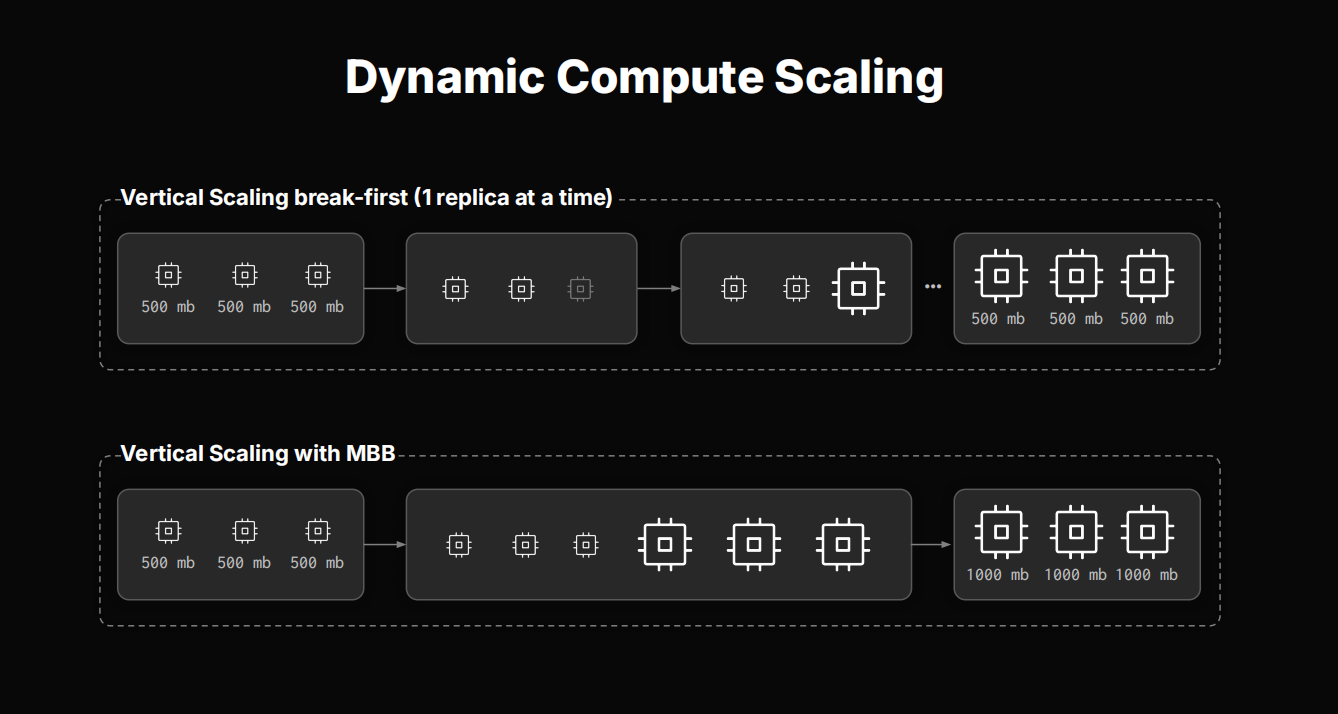
此外,动态计算扩缩容(Dynamic Compute Scaling)也是云服务的另一大优势。无论是增加副本数还是提升单节点配置,ClickHouse Cloud都能实现秒级响应。部分弹性能力得益于与阿里云等合作伙伴的技术整合,例如通过容器级别的资源调整实现无缝扩展。
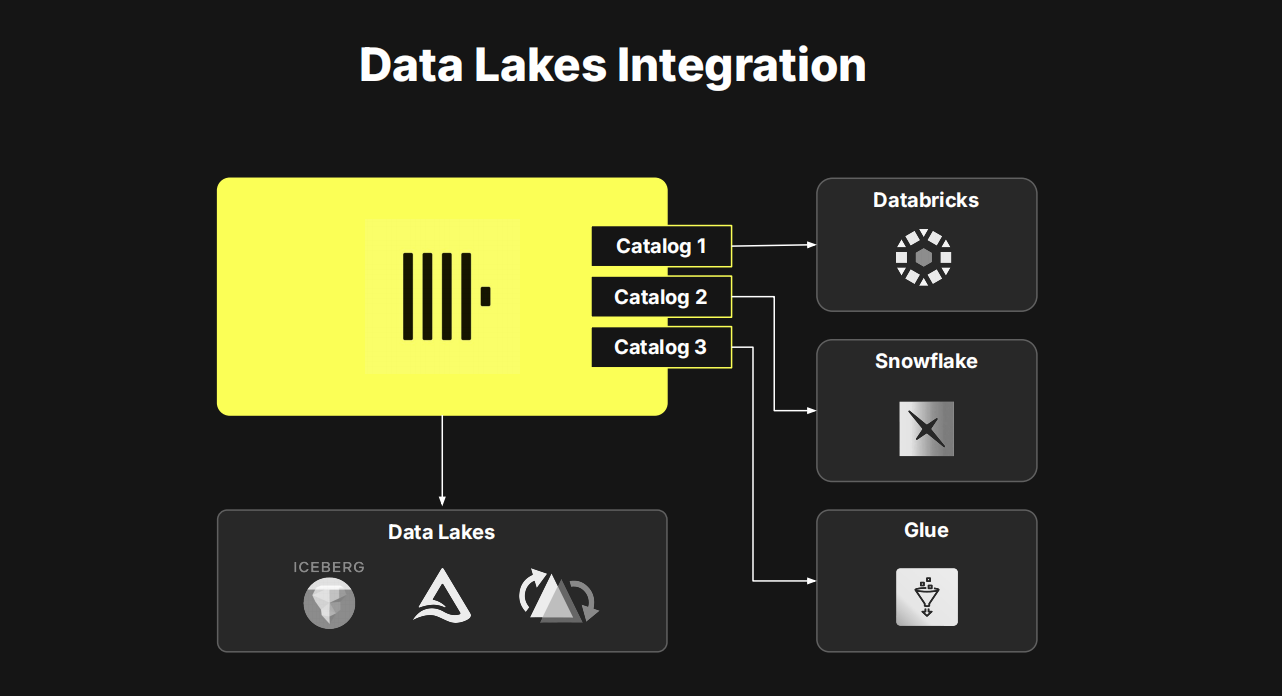
在生态集成方面,ClickHouse Cloud支持多种数据接入方式,包括Kafka、OpenTelemetry等流式与可观测性数据管道,并通过ClickPipes组件实现对各类数据源的无缝对接。近期我们还加强了对DeltaLake的支持,进一步兼容Databricks、Snowflake和AWSGlue等主流数据平台,真正实现了“万物皆可查”的统一数据平台愿景。
全球客户实践:赋能AI与实时分析场景
ClickHouse作为一款高性能的列式数据库,其核心定位始终是实时分析。在全球范围内,尤其是在人工智能与机器学习(AI/ML)领域,ClickHouse已被多家领先企业广泛应用于实际业务场景中,支撑起高并发、低延迟的数据处理需求。
在实时查询方面,我们开发了工具StockHouse,用户可通过该工具对最新公司股价等进行实时分析。
ClickHouse的客户覆盖电商、媒体、金融、汽车等多个行业。国际知名客户包括eBay、沃尔玛、Instacart、Vantage、highlight.io、exabeam、德意志银行等。
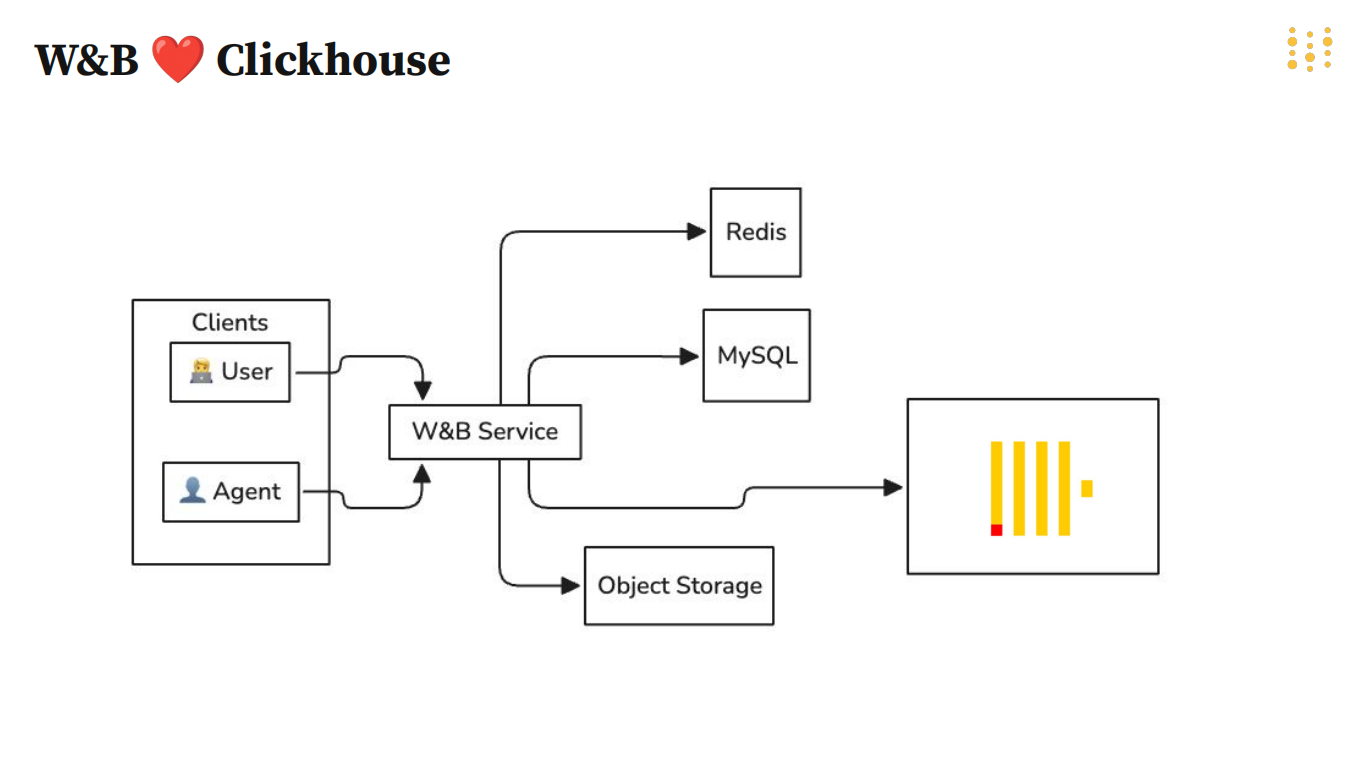
以Weights&Biases(W&B)为例,这家成立于2018年的人工智能公司专注于机器学习样本管理与可视化分析。其旗舰项目ONE DB集成了数据探索、分布分析、多模态数据处理等功能,并与Notebook深度结合,为用户提供便捷的数据分析体验。W&B在生产环境中使用ClickHouse进行大规模监控和训练集存储,其典型架构还包括Redis和MySQL,体现了ClickHouse在混合架构中的灵活性与扩展性。
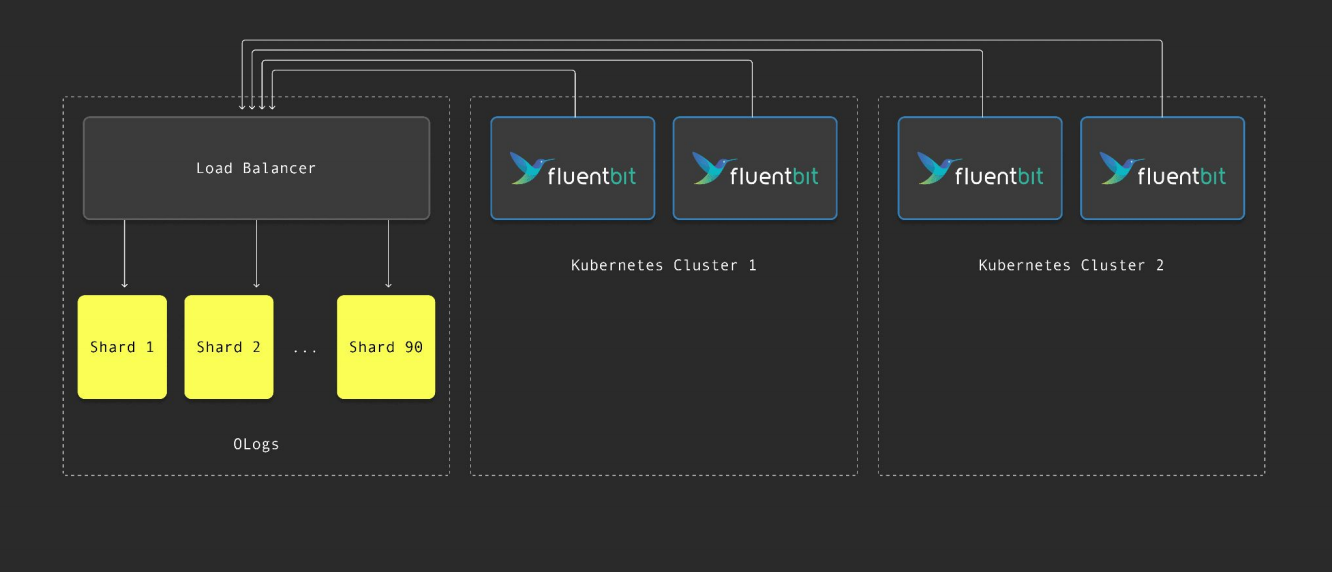
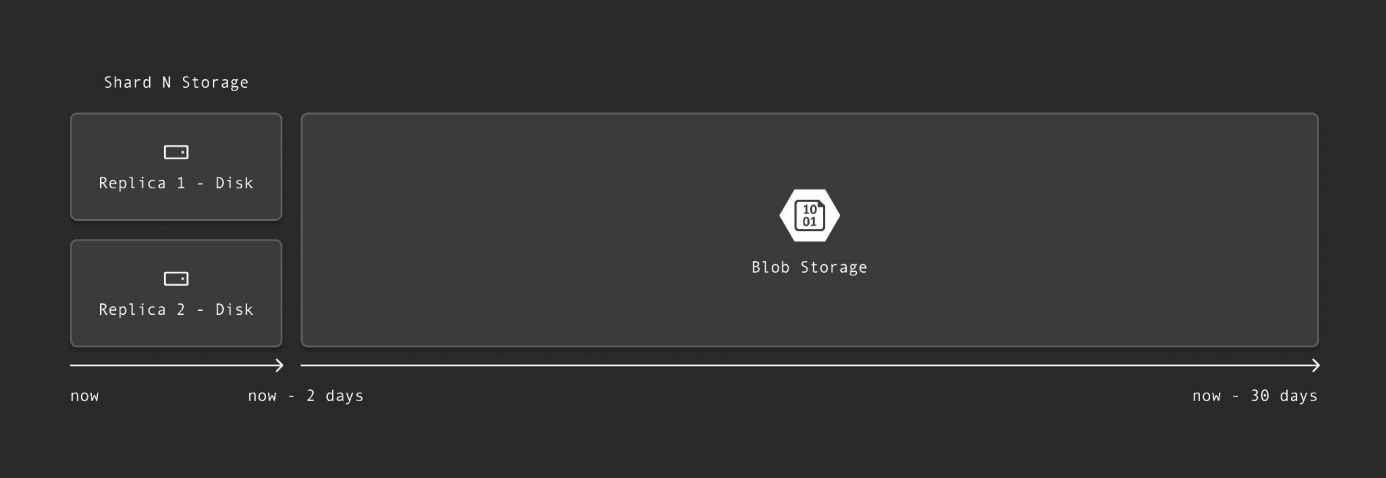
OpenAI则依托ClickHouse构建了可观测性平台,处理每日PB级的日志数据。其架构包含约90个分片,通过负载均衡器将来自Kubernetes集群(经FluentBit收集)的数据写入ClickHouse。热数据(两天内)存储于分片盘中,配备两个副本;冷数据则自动迁移至BlobStorage,实现成本与性能的平衡。
OpenAI在发布GPT-4o图像生成功能后,因“吉卜力动画风格”头像生成功能爆火,流量急剧上升,CPU使用率一度接近100%。工程师通过ClickHouse快速定位到BloomFilter中一个add函数的性能瓶颈,并通过极小的代码改动(将取模运算优化为位操作与哈希组合)显著降低CPU使用率,保障了系统稳定。这一优化虽小,却体现了ClickHouse代码的可维护性与高性能设计。
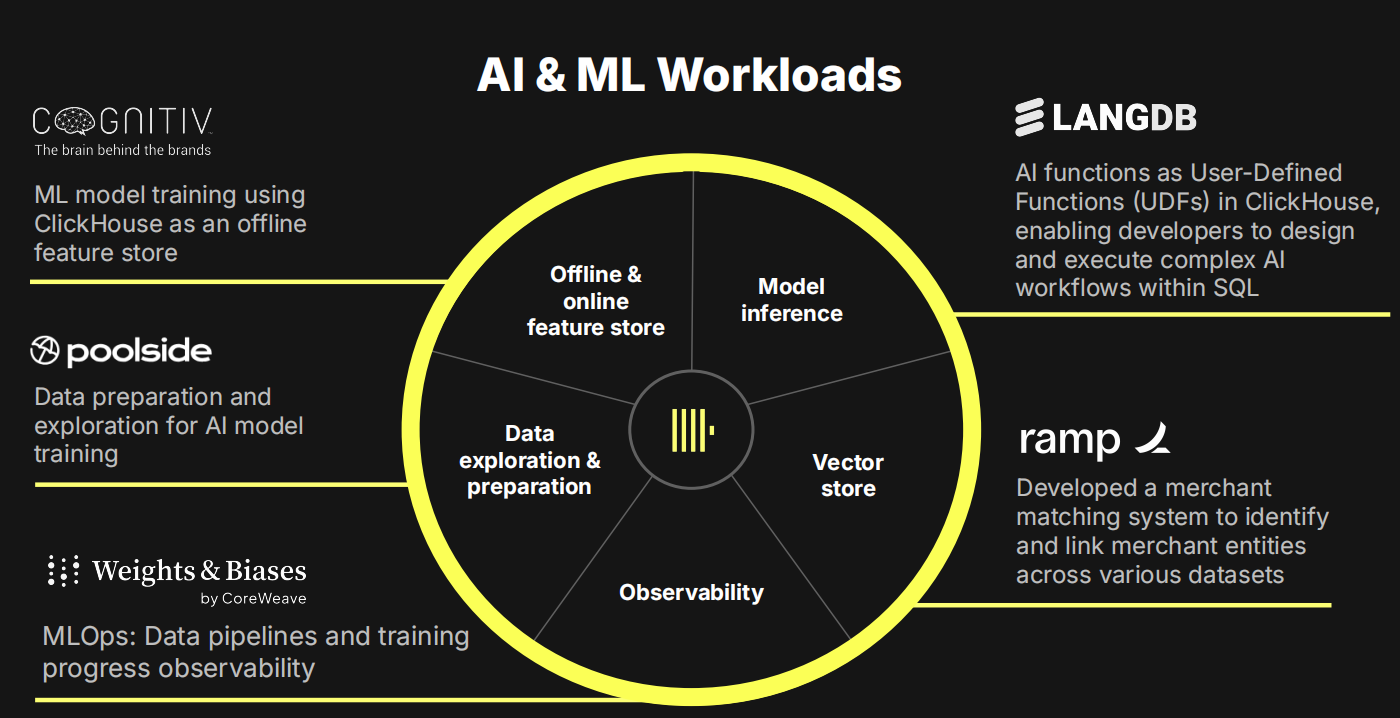
在AI/ML全链路中,ClickHouse广泛应用于数据准备与探索、离线与在线特征存储、模型训练与推理、向量存储及系统可观测性等环节。例如:
W&B在数据准备阶段使用ClickHouse;
Poolside和Cognitiv将其作为离线和在线特征存储,利用物化视图构建大宽表,适配机器学习特征工程需求;
LangDB在模型推理环节集成ClickHouse;
ramp则将其用作向量数据库,尽管这一能力尚未大规模宣传。
面向智能代理(Agent)的AI原生未来
我们正迈入一个由AI智能体(Agent)驱动的时代。这为数据分析带来了新的范式转变:未来的查询可能不再由专业的分析师手动编写SQL,而是由AI Agent自动生成和执行。这将导致数据仓库的查询量和复杂度呈指数级增长。
为应对这一趋势,ClickHouse推出了MCP(Model Context Protocol)Server,实现与AI Agent的自然语言交互。用户不再需要编写复杂的SQL语句,而是通过提示词(prompt)直接表达分析意图。MCP Server通过三个核心函数——list_database、list_table 和 rent_query(即运行查询),为Agent提供结构化访问能力。现在,用户只需用自然语言提出问题(如“分析一下伦敦的房价”),Agent就能自动发现相关数据表、理解结构、编写并执行SQL,最终返回洞察结果。
这一功能已在 llm.ClickHouse.com 上线,用户可免费体验基于自然语言的数据查询。该平台托管了包括房价、经济指标在内的多个公开数据集,用户无需本地部署即可快速构建分析应用。尽管这项服务带来了可观的模型调用成本,但其展示出的交互体验与技术前景,已为ClickHouse在资本市场赢得高度认可。
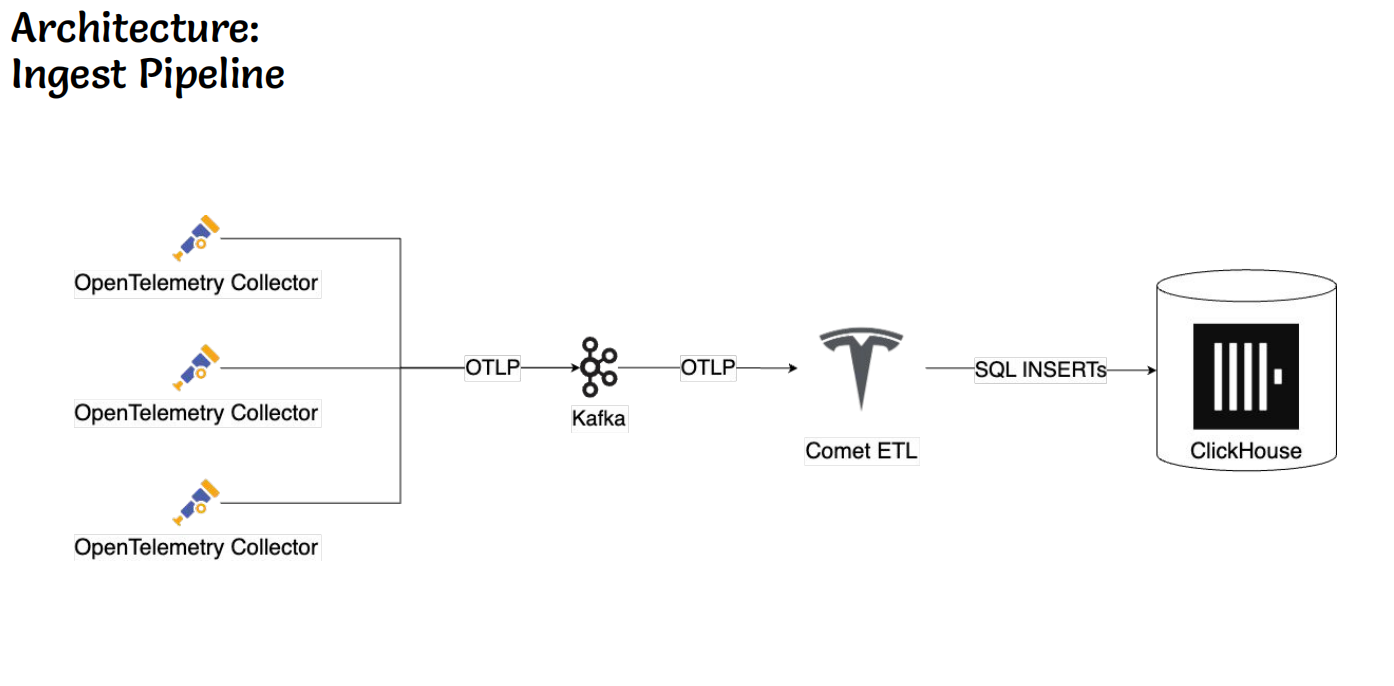
在典型客户实践中,特斯拉基于ClickHouse构建了高性能实时监控系统,通过OpenTelemetry采集数据,经Kafka接入,由Comet ETL服务转换为SQL并写入ClickHouse,支撑每秒十亿行级别的数据吞吐,满足其大规模监控与告警需求。其测试数据规模达到“亿亿”行级,充分验证了ClickHouse在极端负载下的稳定性与扩展性。
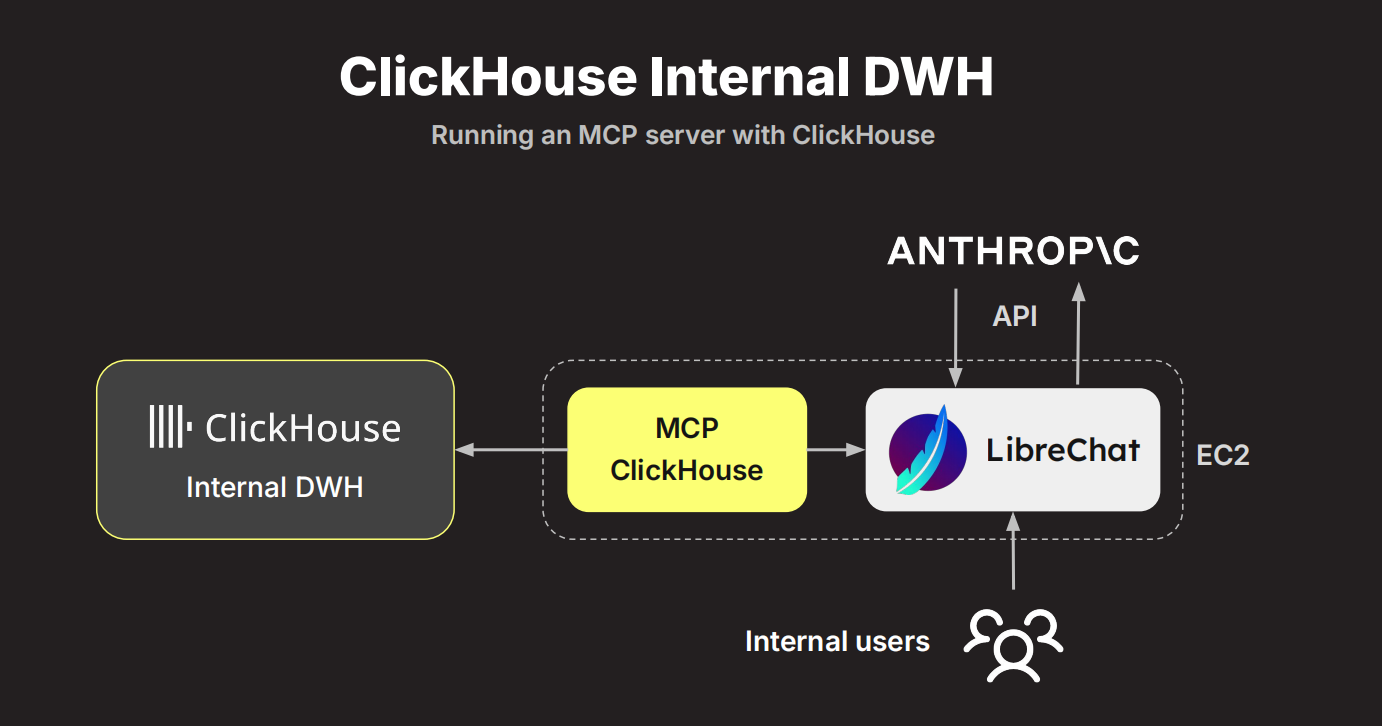
整体架构体现“能用现成服务则不做自研”的理念,以ClickHouse为核心,配合MCP协议与LibreChat等工具快速集成,实现对多源数据的统一接入与智能查询。
ClickHouse for AI/ML 的布局

在数据准备与探索阶段,ClickHouse 提供了多样化的部署与使用方式。用户可通过 clickhouse-local、clickhouse-server 乃至嵌入式引擎 chDB,灵活构建数据探索环境。它不仅可作为高效的 Feature Store 和 Vector Store,还支持用户定义函数(UDF),甚至允许将推理函数封装为UDF在数据库内直接执行,极大简化了AI与数据的集成流程。
向量检索是AI应用中的关键能力。早期数据库常将向量视作普通列处理,导致查询效率低下、开发体验差,用户需手动编写余弦相似度等复杂函数。如今,ClickHouse 已将向量当做index,用HNSW做L2Distance,然后直接当成index查询值用,用户无需编写复杂SQL即可实现高效相似性查询。未来,随着SDK的进一步完善,向量计算还将在插入时自动完成,并支持 BFloat16 及 int8 量化,进一步降低存储与计算开销。

总结来说,面向Agent时代的数据引擎需具备多项核心能力。首先,必须是高性能实时引擎;用户的耐心有限,T+1的延迟已无法满足市场需求。其次,需支持基于上下文的分析(Analytics in context),能够理解并组织用户问题中的上下文,甚至实现记忆机制;再次是实时数据,不想T+1;最后,统一数据访问(Unified Data Access)也至关重要如RAG,需同时支持向量检索、全文搜索和时间序列查询,一旦数据分散于多处,整个架构将变得复杂且难以维护。
为集中展示我们在AI方面的成果,我们正式推出 ClickHouse.ai,该平台整合了相关功能、案例与资源,欢迎开发者与数据科学家访问探索,体验ClickHouse为智能应用带来的强大助力。
欢迎浏览ClickHouse官网www.clickhouse.com或者关注微信公众号‘ClickHouseInc’获得更多更快的产品更新信息。
ClickHouse企业版已正式上线阿里云,这是一款基于ClickHouse开源技术打造的新一代云原生Serverless实时数据仓库产品。阿里云ClickHouse企业版依托存算分离的云原生架构,在显著提升查询性能与执行效率的同时,支持更高效的计算与存储资源管理,降低了大规模数据存储场景下的存储成本、水平扩缩容等运维场景对业务的影响时间和工作量,并通过Serverless能力提升了业务在突发高峰下的稳定性、降低了业务的闲时资源浪费。
此外,阿里云ClickHouse企业版还支持跨可用区(AZ)高可用部署,并集成低成本S3类存储,确保数据的可靠性与经济性,帮助企业从容应对数据量快速增长带来的存储成本压力 。

