看得清、做得好、拟得真:蚂蚁灵波科技开源三款具身领域模型探索AGI边界
临近农历春节,中国模型领域又开始卷了起来,这一次蚂蚁在具身领域为业内带来了惊喜。

本周,蚂蚁集团旗下灵波科技自1月27日起三天内接连开源了LingBot-Depth、LingBot-VLA、LingBot-World三款具身领域大模型,意味着蚂蚁的AGI战略实现了从数字世界到物理感知的关键延伸,标志着其“基础模型-通用应用-实体交互”的全栈路径已然清晰。
理想的具身智能机器人能够与物理环境交互并与人自然交流,并具备自主“感知—认知—决策—行动”的能力,上述每个环节都有不小的挑战。
比如感知环境方面,想让机器看得清楚并不容易。在家庭和工业环境中,玻璃器皿、镜面、不锈钢设备等透明和反光物体物体十分常见,但却是机器空间感知的难点。传统深度相机受制于光学物理特性,在面对透明或高反光材质时,往往无法接收有效回波,导致深度图出现数据丢失或产生噪声。
看得清:强化机器的“视力”
蚂蚁灵波科技开源的高精度空间感知模型LingBot-Depth在“看清楚”三维世界这一行业关键难题上取得了重要突破。
作为一种面向真实场景的深度补全模型,LingBot-Depth旨在将不完整且受噪声干扰的深度传感器数据转化为高质量、具备真实尺度的三维测量结果。
为此,蚂蚁灵波科技研发了“掩码深度建模”(Masked Depth Modeling,MDM)技术,当深度数据出现缺失或异常时,LingBot-Depth模型通过MDM机制能够融合彩色图像(RGB)中的纹理、轮廓及环境上下文信息,对缺失区域进行推断与补全,输出完整、致密、边缘更清晰的三维深度图。
据悉,奥比中光Gemini 330系列双目3D相机在应用LingBot-Depth后,面对透明玻璃、高反光镜面、强逆光及复杂曲面等极具挑战的光学场景时,输出的深度图依然平滑、完整,且物体的轮廓边缘非常锐利,其效果显著优于业内领先的3D视觉公司Stereolabs推出的ZED Stereo Depth深度相机。蚂蚁灵波科技已与奥比中光达成战略合作意向。奥比中光计划基于LingBot-Depth的能力推出新一代深度相机。
在NYUv2、ETH3D等权威基准评测中,LingBot-Depth相比业界主流的PromptDA与PriorDA,其在室内场景的相对误差(REL)降低超过70%,在挑战性的稀疏SfM 任务中RMSE误差降低约47%,确立了新的行业精度标杆。
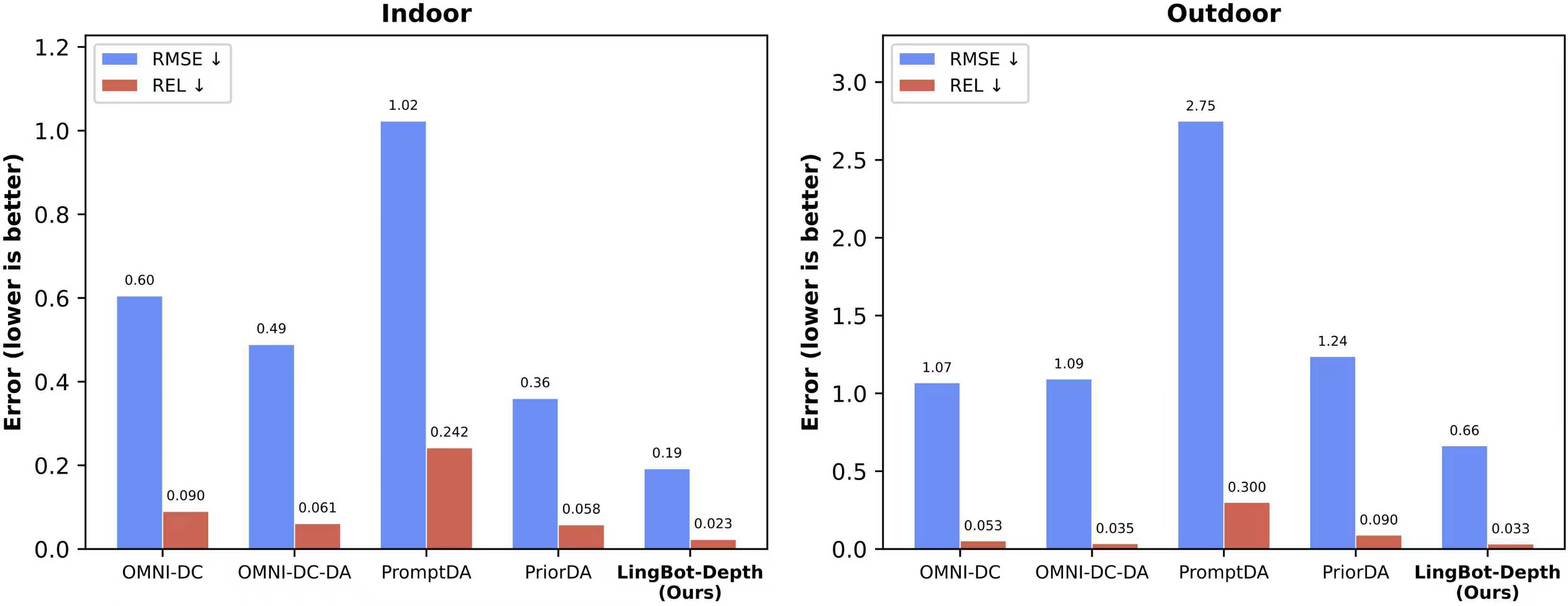
(在最具挑战的稀疏深度补全任务中,LingBot-Depth性能整体优于现有多种主流模型。图中数值越低代表性能越好。)
LingBot-Depth的优异性来源于海量真实场景数据,据悉,灵波科技采集约1000万份原始样本,提炼出200万组高价值深度配对数据用于训练,支撑模型在极端环境下的泛化能力。这一核心数据资产(包括2M真实世界深度数据和1M仿真数据)将于近期开源,推动社区更快攻克复杂场景空间感知难题。
可以说LingBot-Depth强化了机器的“视力”,让机器看得更清楚,这还远远不够,机器能够做好“认知—决策—行动”还需要一个强大的“大脑”,也就是具身智能基座模型。
做得好:一个通用的具身智能“大脑”
长期以来,由于本体差异、任务差异、环境差异等,具身智能模型落地面临严重的泛化性挑战。开发者往往需要针对不同硬件和不同任务重复采集大量数据进行后训练,直接抬高了落地成本。
蚂蚁灵波科技开源的具身大模型LingBot-VLA,旨在打造一个通用具身智能“大脑”,让机器能够做明白。
目前LingBot-VLA已经实现了跨本体、跨任务泛化能力,并大幅降低了后训练成本,在真机和仿真评测中获得佳绩。
在上海交通大学开源的具身评测基准GM-100(包含100项真实操作任务)测试中,LingBot-VLA在3个不同的真实机器人平台上,跨本体泛化平均成功率相较于Pi0.5的13.0%提升至15.7%(w/o Depth)。引入深度信息(w/ Depth)后,平均成功率进一步攀升至17.3%,刷新了真机评测的成功率纪录,验证了其在真实场景中的性能优势。
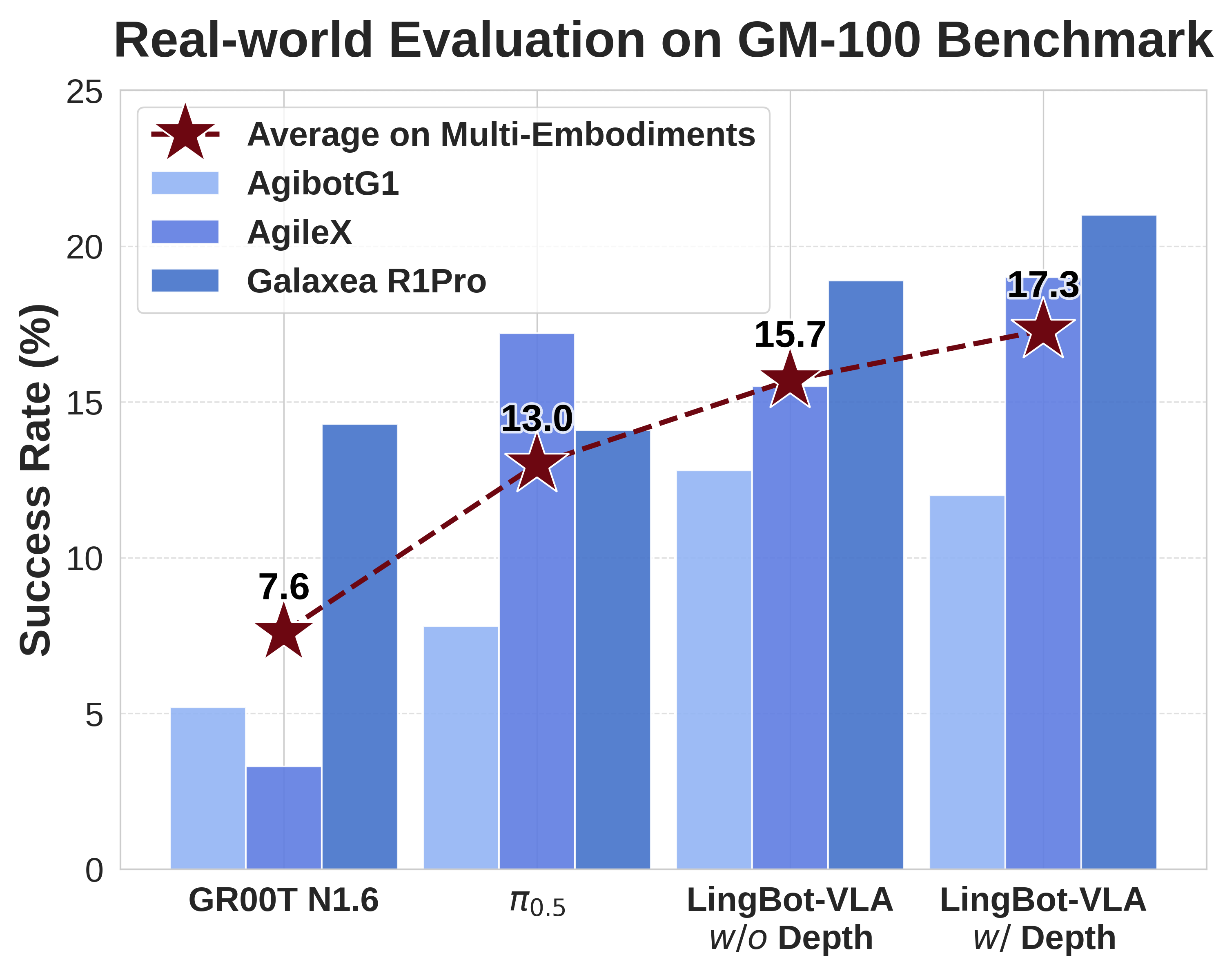
(在GM-100真机评测中,LingBot-VLA 跨本体泛化性能超越 Pi0.5)
在RoboTwin 2.0仿真基准(包含50项任务)评测中,面对高强度的环境随机化干扰(如光照、杂物、高度扰动),LingBot-VLA凭借独特的可学习查询对齐机制,高度融合深度信息,操作成功率比Pi0.5提升了9.92%。
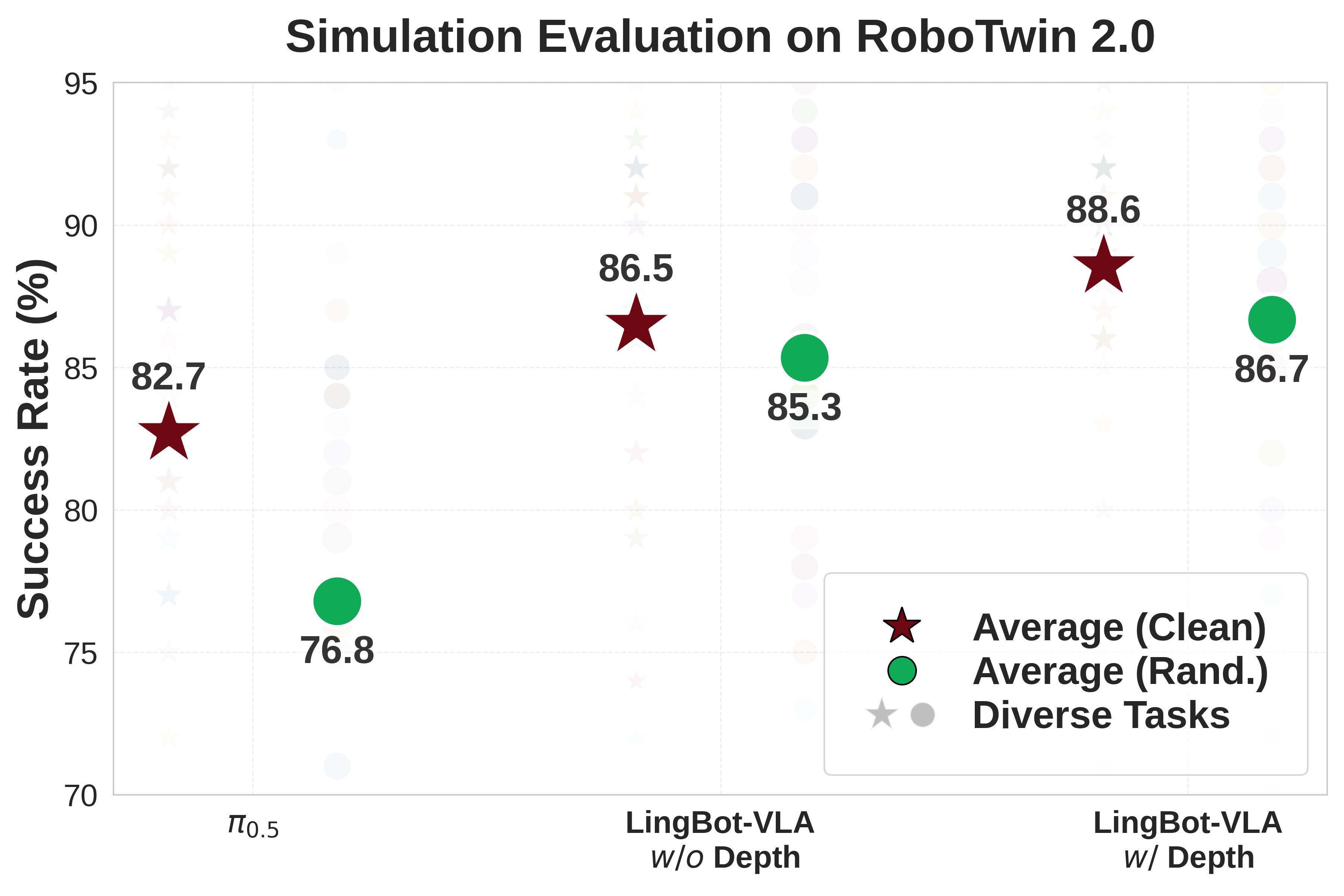
(在RoboTwin 2.0仿真评测中,LingBot-VLA跨任务泛化性能超越Pi0.5)
据悉,LingBot-VLA基于20000+小时大规模真机数据进行预训练,覆盖了9种主流双臂机器人构型(包括 AgileX,Galaxea R1Pro、R1Lite 、AgiBot G1等),从而让同一个“大脑”可以无缝迁移至不同构型的机器人,并在任务变化、环境变化时保持可用的成功率与鲁棒性。
与高精度空间感知模型LingBot-Depth配合,LingBot-VLA能获得更高质量的深度信息表征,通过“3D视野+VLA”的组合让机器在更加贴近现实世界的3D物理环境完成交互感知,以做出更好的决策执行。
此外,LingBot-VLA凭借扎实的基座能力,大幅降低了下游任务的适配门槛,仅需80条演示数据即可实现高质量的任务迁移。此次开源LingBot-VLA不仅提供了模型权重,还同步开放了包含数据处理、高效微调及自动化评估在内的全套代码库。这一举措大幅压缩了模型训练周期,开发者以更低成本快速适配自有场景。
LingBot-VLA的实践突破印证了具身智能领域Scaling Law定律的有效性,为尚在探索初期的具身智能领域带来了信心。
拟得真:对标Genie 3的世界模型LingBot-World
LingBot-World是蚂蚁灵波科技开源发布的第三款具身领域模型,该世界模型旨在为具身智能、自动驾驶及游戏开发提供高保真、高动态、可实时操控的“数字演练场”。目前,LingBot-World 模型权重及推理代码已面向社区开放。
据悉,LingBot-World在视频质量、动态程度、长时一致性、交互能力等关键指标上均媲美Google Genie 3。

(LingBot-World在适用场景、生成时长、动态程度、分辨率等方面均处于业界顶尖水平)
视频生成最常见的是“长时漂移”问题,即模型在生成长时间视频序列时,由于对场景内容、物体结构或运动轨迹的“记忆”能力不足,导致生成内容随时间逐渐偏离初始设定,出现物体变形、背景穿帮、风格突变或逻辑混乱等现象。这被视为构建高保真“世界模型”的核心挑战之一。
业内主要通过引入长效记忆机制和多模态感知信息来提升生成的一致性,LingBot-World通过多阶段训练以及并行化加速,实现了近10分钟的连续稳定无损生成,可以很好地为长序列、多步骤的复杂任务训练提供支撑。
在交互性能上,LingBot-World能够实现约16 FPS的生成吞吐,并将端到端交互延迟控制在1秒以内,实现实时操控反馈。
相比于大语言模型,具身智能领域的真实物理数据更显不足,真机数据采集成本比较高昂,这也制约了具身智能的发展。
实际上,具身智能不仅可以使用真机采集的真实数据,还可以使用世界模型生成的仿真数据,并且这一方向正成为推动该领域发展的重要路径。随着世界模型的发展,其所搭建的高仿真环境将会成为加速具身智能进化的土壤。
LingBot-World凭借长时序一致性(也即记忆能力)、实时交互响应,以及对“动作-环境变化”因果关系的理解,在高保真的数字化模拟物理世界中,为智能体的场景理解和长程任务执行提供了一个低成本、高保真的试错空间。同时,LingBot-World支持场景多样化生成(如光照、摆放位置变化等),也有助于提升具身智能算法在真实场景中的泛化能力。
蚂蚁灵波科技CEO朱兴表示,蚂蚁集团坚定以开源开放模式探索 AGI,为此打造 InclusionAI,构建了涵盖基础模型、多模态、推理、新型架构及具身智能的完整技术体系与开源生态。蚂蚁正通过InclusionAI社区将模型全部开源,和行业共建,探索AGI的边界。
目前,具身智能领域尚未形成统一共识,仍处于技术路径多元、发展方向探索的早期阶段,日拱一卒,功不唐捐。相信开源会加速创新探索和规模化落地的进程。

