无限的等待如何将缓慢变成中断。

在面向用户的分布式系统中,延迟通常比错误更强烈地表示故障。当响应超出用户预期时,“慢”和“下降”之间的区别在很大程度上变得无关紧要,即使每项服务在技术上都是健康的。
我在多个系统中都看到了这种模式。特别是,一个事件迫使我面对有多少生产行为是由我们从未明确选择的默认情况塑造的。突出的不是缓慢本身,而是“默认无限”的等待如何在任何事情超过传统的故障阈值之前悄悄耗尽容量。
详细信息是通用的,以避免共享专有信息。
當慢速變成停電時
事件始于支持票,而不是警报。清晨,他們開始出現:
产品页面无法加载。
结账卡住了。
网站今天很慢。
与此同时,我们的仪表板以微妙的方式漂移。CPU上升,内存压力增加,线程池已满,而错误率保持在低水平。产品页面开始间歇性挂起:一些请求已完成,其他请求停滞不前,用户刷新,打开新标签,最终离开。
那周我待命了。最近有一个部署,所以我提前把它卷回去了。它沒有效果,這告訴我們,问题不是具体的變化,而是系統在持續緩慢下的行為方式。
在几个小时内,影响是可以衡量的。产品页面放弃率急剧增加。转化率下降了两位数。支持票数量激增。用户开始转向竞争对手。到当天结束时,该事件造成了六位数的损失,更重要的是,用户信任的明显损失。
更难的问题不是什么失败了,而是为什么用户影响在我们的页面被触发之前就出现了。系统早在超过任何分页阈值之前就越过了用户的疼痛阈值。我们的警报针对硬性故障进行了优化——错误、实例运行状况、显式饱和度——而延迟存在于仪表板上,而不是在分页中。
我们错过的失败模式
产品页面以用户的当地货币显示价格。为此,产品服务调用了下游货币兑换API。这种依赖性并没有下降。它变得缓慢,断断续续,足够长的时间来触发级联。
当我在事件中深入挖掘时,一个细节脱颖而出。产品服务使用具有默认配置的HTTP客户端,其中请求超时实际上是无限的。在前端,浏览器在大约30秒后停止等待。在后端,在用户已经放弃后,请求继续等待很长时间。
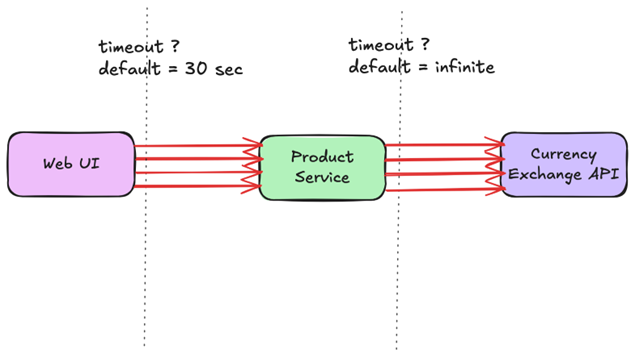
这个差距比我预想的更重要。前几个挂起的货币呼叫保留在产品服务工作者线程和出站连接上,因此新的请求开始在另一端不再有用户的工作后面排队。一旦共享池开始饱和,它就不再是“唯一的货币路径”。即使是不需要货币转换的请求也会变慢,因为他们等待相同的线程池和相同的内部容量。
那时,依赖项不需要失败来关闭服务。当我们继续无界限地等待时,它只需要变慢。这不是错误失败。这是一个容量故障。受阻的并发累积的速度超过了消耗的速度,延迟向外传播,吞吐量崩溃,没有抛出任何异常。
一些缓解措施只是暂时的。重启实例或减少交通量在短时间内减轻了压力,但缓解从未持续过。只要允许请求无限期地等待,系统就会以超过完成速度不断积累工作。
当我们最终确定无限的等待时,立即修复听起来很简单:设置超时。真正的教训是更深的。
悄悄塑造系统行为的默认值
乍一看,这看起来像是一个简单的配置错误。实际上,它反映了常见的默认设置如何影响生产中的系统行为。
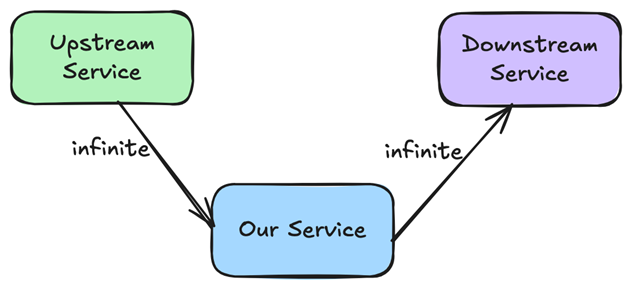
许多广泛使用的库和系统默认为无限或极大的超时。在Java中,除非明确配置,否则常见的HTTP客户端将超时为零视为“无限期等待”。在Python中,除非明确设置超时,否则请求将无限期地等待。Fetch API根本没有定义内置超时。
这些默认值不是粗心大意。它们是故意的通用的。库针对单个请求的正确性进行了优化,因为它们无法知道“太慢”对您的系统意味着什么。部分故障下的生存能力由申请来确定。
生产系统在理想条件下很少出现故障。它们在负载、部分中断、重試和真实使用者行为下失败。在这些条件下,无限的等待变得危险。在开发过程中感觉无害的默认值在生产中悄悄地做出架构决策。
当我们后来作为一个团队审核我们的服务时,我们发现许多呼叫要么没有超时,要么其值不再与实际生产延迟相匹配。多年来,默认值一直塑造着系统行为,而我们没有明确选择它们。
长时间超时背后的心理模型
这一事件揭示的不仅仅是错过超时。它暴露了许多团队所依赖的心理模式,包括我们当时的心理模式。
该模型假设:
依賴性通常很快
慢是很少見的
违约是合理的
等待的时间越长,成功的机会就越大
它优先考虑个人请求的成功,通常以整体系统可靠性为代价。因此,团队通常不知道他们的有效超时,不同的服务使用不一致的值,并且有些通话根本没有超时。
即使存在超时,它们通常比用户行为证明的要长得多。在我们的案例中,用户在几秒钟内重试,并在大约十秒钟内放弃。等待超过这个并没有改善结果。它只消耗了容量。
长时间的超时也可以掩盖更深层次的设计问题。如果请求经常超时,因为它返回了数千个项目,问题不在于超时本身。它缺少分页或请求形状不佳。通过优化个人请求的成功,团队无意中交易了系统级别的弹性。
超时作为故障边界
在这次事件发生之前,我们大多将超时视为配置旋钮。在那之后,我们开始将它们视为失败的界限。
超时定义了允许故障停止的位置。在没有超时的情况下,单个缓慢的依赖项可以悄悄地消耗整个系统的线程、连接和内存。如果选择良好的超时,缓慢度就会保持控制,而不是蔓延到全系统故障。
我们进行了一系列刻意的更改:
1.客户端强制超时
来电者决定何时停止等待。正如事件所表明的那样,负载平衡器、代理或服务器无法可靠地保护我们免受永久挂断。
2.为面向用户的流程引入了明确的端到端截止日期
下游呼叫只能使用剩余的时间预算;超过该点的等待是浪费的工作,没有机会改善结果。
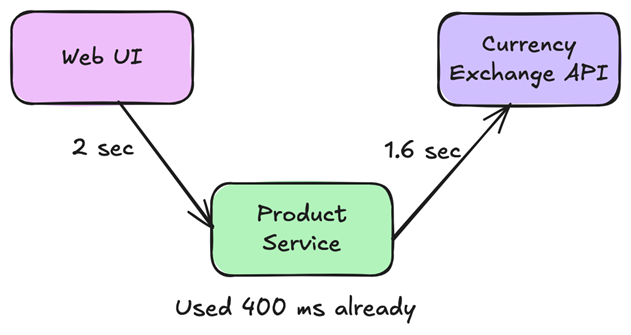
我们使这些截止日期明确且可移植。在HTTP流程中,我们通过单个X-Request-Deadline标头传播端到端截止日期,以便每个服务都可以计算剩余时间,并相应地设置每次调用超时。我们选择了截止日期(不是每跳超时),因为它干净利落地跨越服务边界和重修。
对于gRPC路径,内置截止日期允许剩余时间跨越服务边界传播。我们通过内部请求上下文扩展了相同的边界,因此在预算时,后台工作停止了。
3.开始深思熟虑如何选择超时值
連線超時保持短,並與网络行為相關聯。请求超时是基于实际生产延迟,而不是直觉。
我们没有依赖平均值,而是专注于p99和p99.9。当p50接近p99时,我们留出空间,这样轻微的减速就不会放大为超时峰值。这有助于我们了解慢速请求在负载下的行为,并选择保护容量而不造成不必要的故障的超时。
例如,如果99%的请求在300毫秒内完成,那么350-400毫秒的超时比数十秒提供了更好的平衡。超越这一点发生的事情变成了有意识的产品决策。就我们而言,当货币转换超时时,我们又回到了以主要货币显示价格。用户总是更喜欢不完美的答案,而不是无限期地等待。
我们还在面向用户的路径中保持重試的保守性。不遵守端到端截止日期的重试比不重试更糟糕:在用户已经继续前进后,它增加了工作量。这就是“有帮助的”重试在部分缓慢下变成重试风暴的方式。
作為一個團隊,我們將這些決定編碼成共享的客戶端預設和跨新和現有呼叫路徑的強制性審查清單,以便無限等待不會悄悄返回。
保持超时诚实
超时永远不应该沉默。事件发生后,我们专注于三件事:
1.使超时可观察
每次超时都会发出一个结构化的日志条目,其中包含依赖上下文和剩余时间预算。我们将超时率作为指标来跟踪,并提醒持续增加而不是单个峰值。超时率的上升成为事件发生时的预警信号,而不是惊喜。重要的是,我们更新了分页,以包括影响用户的延迟和“请求未完成”信号,而不仅仅是错误率。
2.停止将超时值视为常量
流量增长,依赖性变化,架构演变,因此一年前合理的价值观在今天往往是错误的。每当流量模式发生变化、引入新的依赖项或延迟分布发生变化时,我们都会审查超时配置。
3.在真实事件强制解决问题之前验证超时行为
在非生产环境中引入人工延迟,迅速暴露了挂起呼叫、重试放大和错过回退。這也迫使我们分出两个不同的問題:哪些在負載下破裂,哪些在慢速下破裂。
传统的负载测试回答了第一个。故障注入和延迟实验揭示了第二个,一种通常被描述为混沌工程的受控故障形式。通过引入受控延迟和偶尔的挂起,我们验证了截止日期实际上停止了工作,队列没有无限制地增长,回退也按预期行事。
向前推进的教训
这件事永久地改变了我对超时的看法。
超时是关于价值的决定。过了一定时间,等待的时间更长并不能改善用户体验。它增加了系统在用户离开后执行的浪费工作量。
超时也是关于遏制的决定。如果没有有限制的等待,部分故障会通过资源枯竭变成全系统故障:被阻止的线程、饱和池、不断增长的队列和级联的延迟。
如果从这个故事中有一个要点,那就是:刻意定义超时,并将其与预算联系起来。从用户行为开始。以p99测量延迟,而不仅仅是平均值。使超时可观察,并明确决定它们发射时会发生什么。隔离容量,以便单个缓慢的依赖项不会耗尽系统。
无限的等待不是中立的。它具有真正的可靠性成本。如果你不刻意限制等待,它最终会为你束缚你的系统。

