匿名“大象”现真身:蚂蚁百灵新模型Ling-2.6-flash正式发布,百万token只需 0.1美元
一周前,一只名为“Elephant Alpha”的匿名模型悄然登陆OpenRouter平台,没有品牌背书、没有任何宣传预热。然而上线仅数日,其调用量便一路飙升,连续多日占据Trending榜首,日均token调用量突破100B级别,周增长率超过5000%。
今天,这只“大象”终于揭开了它的真面目,蚂蚁百灵正式认领,其真实身份正是最新推出的Ling-2.6-flash模型。
“Token效率”是核心卖点
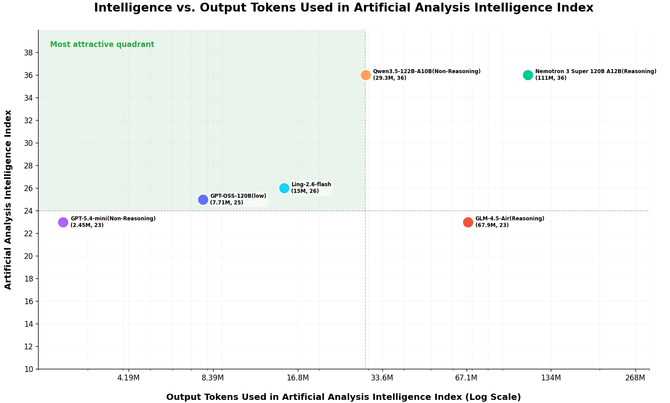
Ling-2.6-flash的token消耗很低,这是一款总参数量104B、激活参数仅7.4B的Instruct模型。它沿用了Ling 2.5的混合线性架构设计,是一种高度稀疏化的MoE(混合专家)架构。简单来说,模型虽然“块头”不小,但每次推理只唤醒7.4B参数来干活,其余参数保持静默。
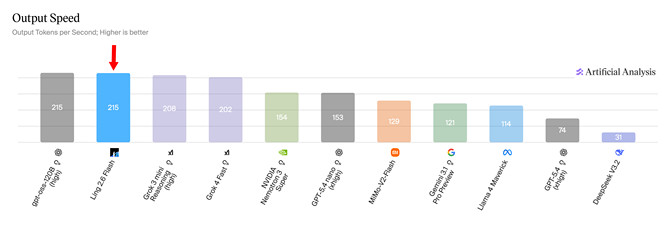
这种设计带来的直接好处就是硬件效率的显著提升。据蚂蚁百灵公布的数据,在4卡H20条件下,Ling-2.6-flash的推理速度最快可达340 tokens/s,Prefill吞吐达到Nemotron-3-Super的2.2倍。在Output Speed测评中,它以215 tokens/s的稳定输出速度位列同参数级别模型的第一梯队。
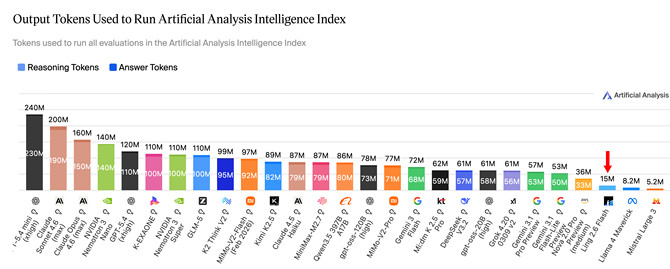
在Token消耗测试中,Ling-2.6-flash只用1/10的消耗完成同等评测。根据权威三方评测机构Artificial Analysis的数据,该模型以15M output tokens实现了26分的Intelligence Index。作为对比,Nemotron-3-Super等模型要达到相近分数,消耗的token量超过110M。
在当下大模型API按token计费的商业模式下,这一优势直接转化为开发者和企业的成本降低。更少的输出token意味着更低的推理开销、更快的首字响应、更短的整体生成时延,以及更流畅的交互体验。
定向增强Agent,同尺寸SOTA“干活多废话少”
值得注意的是,Ling-2.6-flash并非一味追求“省”,而是在控制token消耗的前提下,面向Agent场景进行了定向增强。
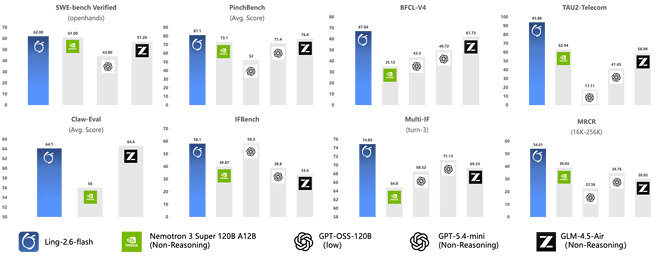
模型在多个Agent相关基准上达到了同尺寸SOTA水平,包括BFCL-V4、TAU2-bench、SWE-bench Verified、Claw-Eval、PinchBench等。其中,BFCL-V4专注于评估模型调用外部工具和API的准确性;TAU2-bench则考察复杂工作流中的任务执行;SWE-bench Verified测试模型解决真实GitHub Issue的能力……都是业界公认的硬核评测集。
与此同时,Ling-2.6-flash在通用知识、数学推理、指令遵循及长文本解析等维度也保持了优秀水准。可以说,这是一款“不偏科”的高效模型。
API定价方面,Ling-2.6-flash输入每百万tokens定价0.1美元,输出0.3美元。这一价格在当前主流模型中具备非常强的竞争力。GPT-5.4 mini输入token定价0.391美元,输出4.5美元。GLM-4.5-Air输入定价0.073美元,输出1.05美元。
目前,Ling-2.6-flash的API已正式向用户开放,并提供为期一周的限时免费试用。用户可以通过OpenRouter或百灵大模型tbox获取对应服务。另据透露,该模型后续还将通过蚂蚁数科发布商业版本LingDT,服务全球开发者及中小企业。
写在最后
从匿名上线即登顶Trending,到正式发布后明确“Token效率”的差异化定位,Ling-2.6-flash展现了一条不同于参数竞赛的路径:用更少的计算资源完成更多的实际任务。对于正在为推理成本头疼的企业和开发者而言,这只“大象”值得一试。

