谷歌以全新TPU芯片、Virgo互连及更快的Lustre加强AI超计算机
谷歌云今天在拉斯维加斯举行的年度Cloud Next用户大会上发布了一系列公告。在基础设施方面,这家云巨头推出了第八代张量处理单元(TPU)以及Virgo——一个全新的“巨型”扩展结构,能够以高达每秒47 Petabit的双向带宽连接不同数据中心的134,000个TPU。此外,它还加强了其托管Lustre产品。
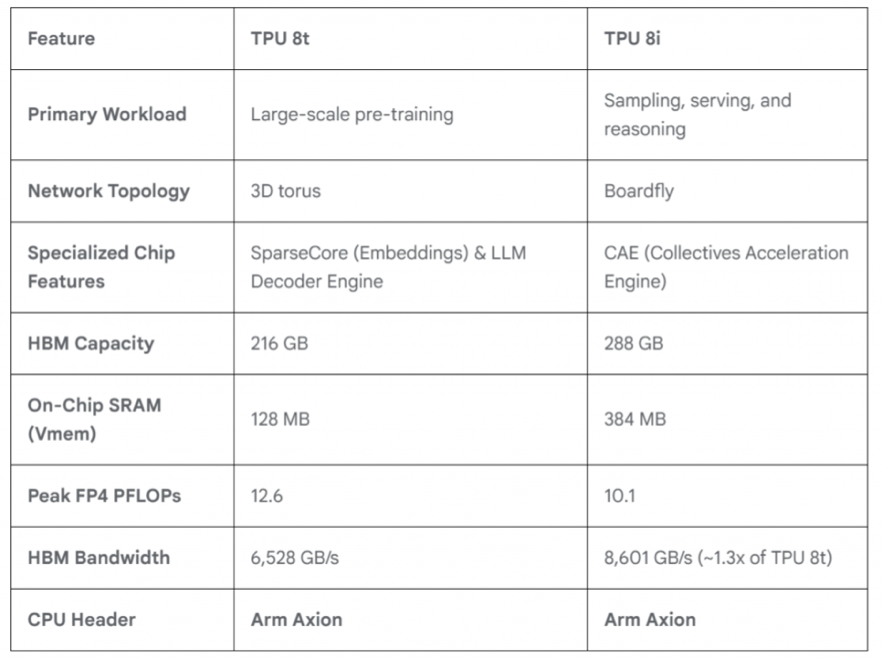
TPU 8i和8t的选定规格(来源:谷歌)
TPU是谷歌为加速机器学习工作负载而创建的定制ASIC。谷歌与博通共同设计、并与台积电合作制造的芯片于2015年首次推出,重点加速8位矩阵乘法。自那时以来,谷歌大约每一年半推出一代新芯片,最新的是2024年推出的“Trillium”TPU和2025年展会上推出的“Ironwood”芯片。
有了第八代TPU,谷歌将其芯片分为两个分支。该公司现在提供用于训练的TPU 8t和用于推理的TPU 8i。
TPU 8t
谷歌表示,TPU 8t的处理能力是第七代Ironwood TPU的3倍,每瓦性能是后者的2倍。具体而言,TPU 8t配备了216 GB的HBM、6,500 GB/s的HBM带宽和128 MB的片上SRAM,提供12.6峰值FP4 Petaflops的计算能力。
TPU 8t还引入了SparseCore,这是一个新的加速器,用于补充现有的矩阵乘法单元(MXU),以处理“嵌入查找中的不规则内存访问模式”,例如All-to-All收集操作。谷歌表示,目标是防止“零操作”瓶颈。此外,它还在芯片的矢量处理单元(VPU)组件中带来了“更平衡”的矢量处理能力。
谷歌工程师Diwakar Gupta和Sabastian Mugazambi在一篇关于新TPU的技术博客文章中写道:“这允许量化、softmax和层归一化与MXU中的矩阵乘法更好地重叠,帮助芯片保持忙碌,而不是等待顺序的矢量任务。”
新芯片引入了原生FP4支持,该公司表示,这有助于克服内存带宽瓶颈,并将MXU吞吐量提高一倍,同时即使在低精度量化下也能保持大型模型的准确性。Gupta和Mugazambi写道:“通过减少每个参数的比特数,该平台最大限度地减少了能耗密集型的数据移动,并允许更大的模型层适合本地硬件缓冲区,以达到峰值计算利用率。”
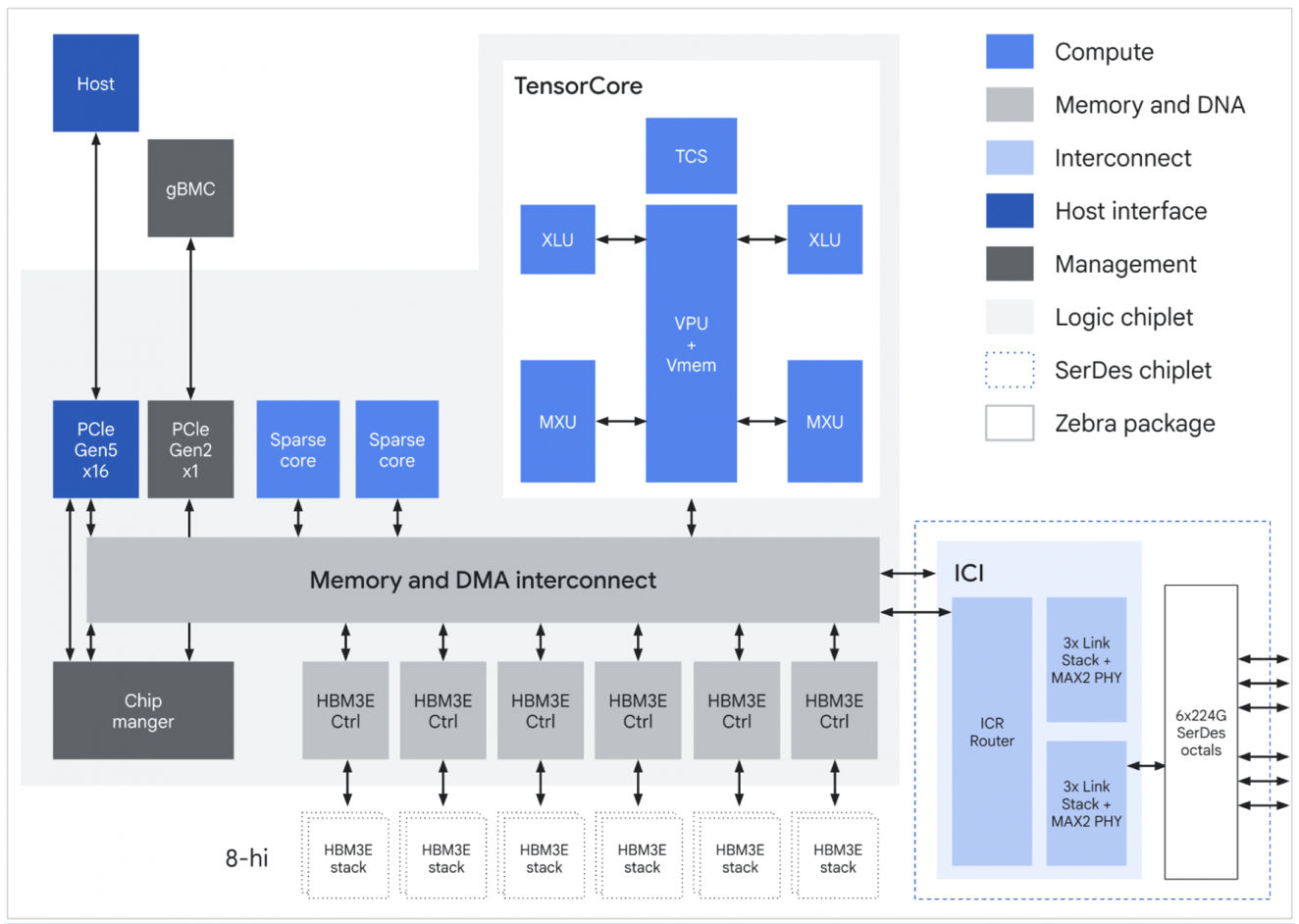
TPU 8t方框图(来源:谷歌)
谷歌还在TPU 8t中推出了TPU Direct RDMA和TPU Direct Storage。TPU Direct RDMA使芯片能够绕过CPU和DRAM,在TPU和高带宽内存之间直接移动数据。类似地,TPU Direct Storage允许数据绕过CPU,将芯片直接连接到高速存储,例如Lustre。谷歌表示,这将“有效地将带宽翻倍”,并允许芯片“以线速率摄入训练数据”。
TPU 8i
TPU 8i提供288 GB的HBM和8,600 GB/s的HBM带宽。它具有384 MB的片上SRAM,SRAM比之前版本的TPU多3倍,使其能够容纳比以前更大的KV缓存。谷歌表示,与Ironwood相比,其每美元性能提升80%。它提供10.1峰值FP4 Petaflops的计算能力。
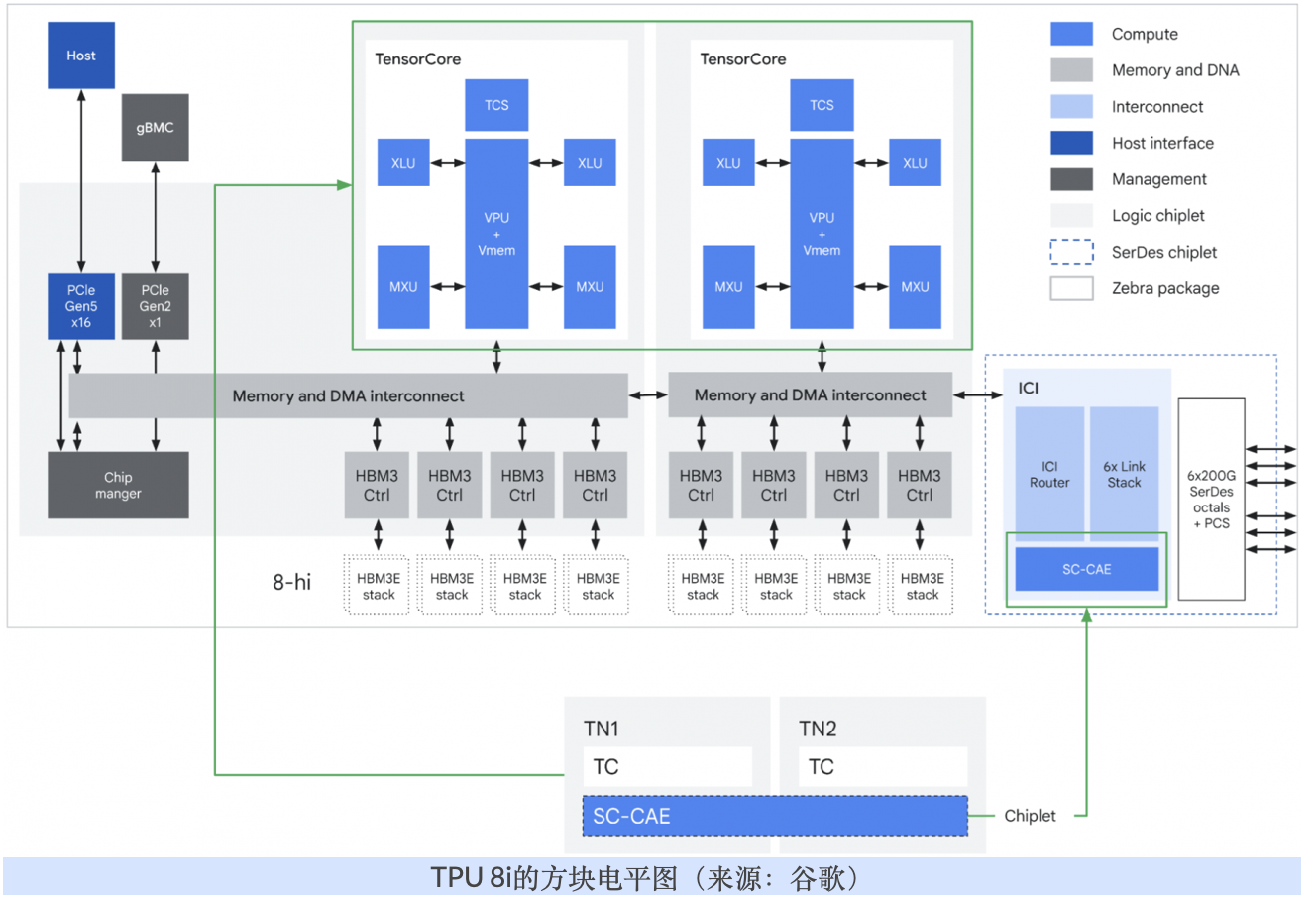
谷歌在TPU 8i中添加了一个新的集体加速引擎(CAE)。该组件用于跨核心聚合结果,以加速解码阶段,并加快“思维链”推理处理。每个TPU 8i芯片将包含两个张量核心(TC)芯粒和一个CAE芯粒,取代了上一代Ironwood TPU中的四个稀疏核心(SC)芯粒。谷歌工程师写道,这将片上的延迟减少5倍,意味着等待时间大幅降低。
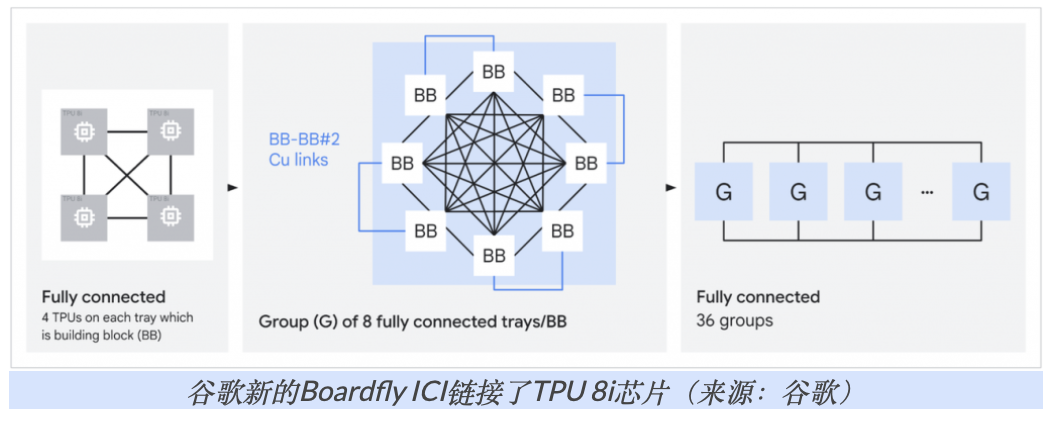
TPU 8i还引入了谷歌新的Boardfly ICI(芯片间互连)拓扑结构,以取代与TPU 8t一起使用的3D环形互连。Boardfly ICI中的每个托盘使用内部ICI链接形成四芯片环或积木块。然后,它使用铜连接八个积木块,创建一个本地化组。接着,它使用光电路开关(OCS)连接多达36个组,共计多达1024个有源芯片。
该公司表示,这种架构确保了任何芯片到芯片通信的最大延迟为七跳。谷歌工程师写道:“通过削减全向全通信(MoE和推理模型的核心)所需的跳数,Boardfly实现了通信密集型工作负载的延迟提升高达50%。”
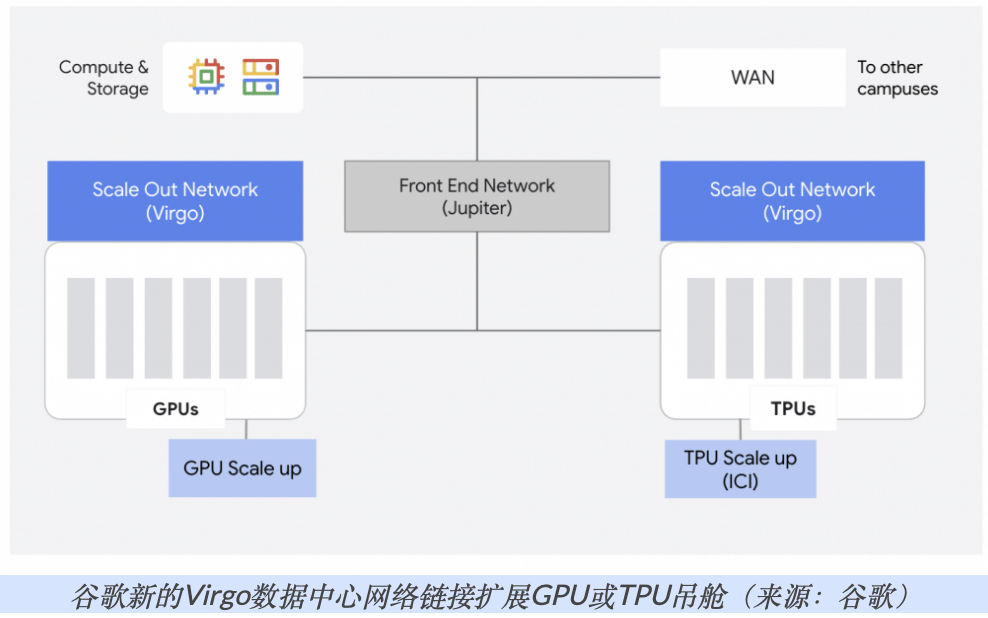
Virgo网络
谷歌还宣布了Virgo网络,这是一种新的高带宽、低延迟互连结构,旨在与其扩展数据中心网络协同工作,作为其AI超计算机的骨干。该公司表示,需要“重新构想”数据中心网络,以解决其Jupiter数据中心网络在规模和延迟上的限制,尤其是在推出新的TPU 8t芯片时。
谷歌早在2015年就推出了Jupiter网络,当时它可以在谷歌数据中心之间提供1.3 Pb/s的双向带宽。2024年,它推出了第五代Jupiter数据中心网络,该网络可以扩展到13 Pbps的双向带宽。谷歌计划继续使用Jupiter作为其前端网络,以处理从一个数据中心到另一个数据中心的“南北向”流量。但在数据中心内部,它正在采用Virgo来处理机柜(可能是TPU或GPU的机架)之间的“东西向”流量,从而以扩展配置进行组装。
谷歌产品经理兼工程研究员Arjun Singh和Benny Siman-Tov写道:“它建立在高基数交换机之上,通过允许每个交换机更多端口来减少网络层级,采用扁平的二层非阻塞拓扑结构。” “与传统的数据中心网络相比,这通过最小化网络层级来显著降低延迟。”
谷歌表示,Virgo可以以高达每秒47 Petabit的速度连接多达134,000个TPU 8t处理器,提供160万ExaFlops的容量,并具有“线性”的扩展性能。谷歌还表示,与上一代相比,该网络支持远程直接内存访问(RDMA),为TPU提供了40%的结构延迟卸载,为延迟敏感的AI工作负载带来了更可预测的性能。
存储增强
谷歌在大会上发布了几项与存储相关的公告。首先,它宣布加强了其Managed Lustre产品,以提供更高的连接速度。该公司表示,其Lustre存储现在可以利用前述的RDMA连接,向其基于Nvidia Vera Rubin NVL72系统的新裸机计算产品A5X或其TPU 8t实例提供每秒10 TB的吞吐量。
谷歌云存储副总裁兼总经理Sameet Agarwal和高级产品管理总监Asad Khan在一篇关于存储公告的博文中写道,这是一年内速度提升了10倍。此外,他们写道,10 TB/s的吞吐量比其他超大规模云厂商的托管Lustre产品(针对单个实例)高出4倍到20倍。
谷歌为Managed Lustre集群推出了一个新的“动态层”,可以为AI工作负载提供低延迟性能。Agarwal和Khan写道:“通过从持久磁盘提供数据,而不是依赖基于对象的缓存,我们消除了性能悬崖——有助于确保您的数据保持响应,加速器保持高效。”动态层每月每GB收费0.06美元。
谷歌还宣布了对Cloud Storage Rapid(或称Rapid Storage)的一些改进,该存储产品基于其一年前推出的Colossus集群级文件系统。谷歌表示,存储在Rapid存储桶(兼容S3)中的数据可以以高达每秒15 TB的速度传输到基于GPU或TPU的系统,比之前支持的6 TB/s峰值快两倍以上。在此配置下,Colossus可以每秒服务2000万个请求,延迟为亚毫秒级,这有助于加载AI训练数据并减少检查点期间的等待时间。
谷歌还升级了Rapid Cache,这是Cloud Storage Rapid的一个组件,以前称为Anywhere Cache。谷歌表示,Rapid Cache可以为某些工作负载(例如用于推理的模型加载)提供高达2.5 TB/s的读取带宽。谷歌还表示,它推出了一项新的“写入后导入”功能,该功能将提供高达2.2倍的检查点恢复速度。
最后,谷歌宣布了对其去年推出的智能存储产品的一些更新。智能存储是云存储中的一项功能,它使每个对象都具有自我描述性。随着自动标注的增加,智能存储库可以自动创建注释,使数据更易于使用和查找。此外,它还宣布了云存储MCP服务器,允许用户使用MCP协议读取、写入和分析云存储中的数据。

