RAG 即检索增强生成(Retrieval - Augmented Generation ),是一种结合检索技术和生成模型的人工智能方法。
Weaviate 是一个开源的向量数据库, 面向的就是RAG使用场景,给出了七种RAG架构cheat sheet。
RAG 分为两个阶段:索引阶段 和 查询阶段,每个阶段都有硬核技术加持!💡
索引阶段 📂
Embedding model:嵌入模型,把数据变成低维向量,计算机秒懂! Generative model:生成模型,文本、图像随便生成,创意无限! Reranker model:重排序模型,检索结果重新排,相关性拉满! Vector database:向量数据库,存储向量数据,检索快到飞起! Prompt template:提示模板,指导模型生成特定格式,输出超精准!
查询阶段 🔍
Multimodal embedding model:多模态嵌入模型,图像、文本全搞定,统一嵌入表示! Multimodal generative model:多模态生成模型,多种数据结合生成,输出超丰富! LLM Graph Generator:大语言模型图生成器,生成图结构数据,复杂关系轻松搞定! Graph database:图数据库,存储图结构数据,图查询操作超高效! AI agent:AI 代理,代表用户执行任务,决策交互超智能!
7 种 RAG 架构 🧩
以下是Weaviate官方总结的七种RAG(Retrieval-Augmented Generation)架构的核心要点速查表,涵盖核心原理、优缺点及适用场景。
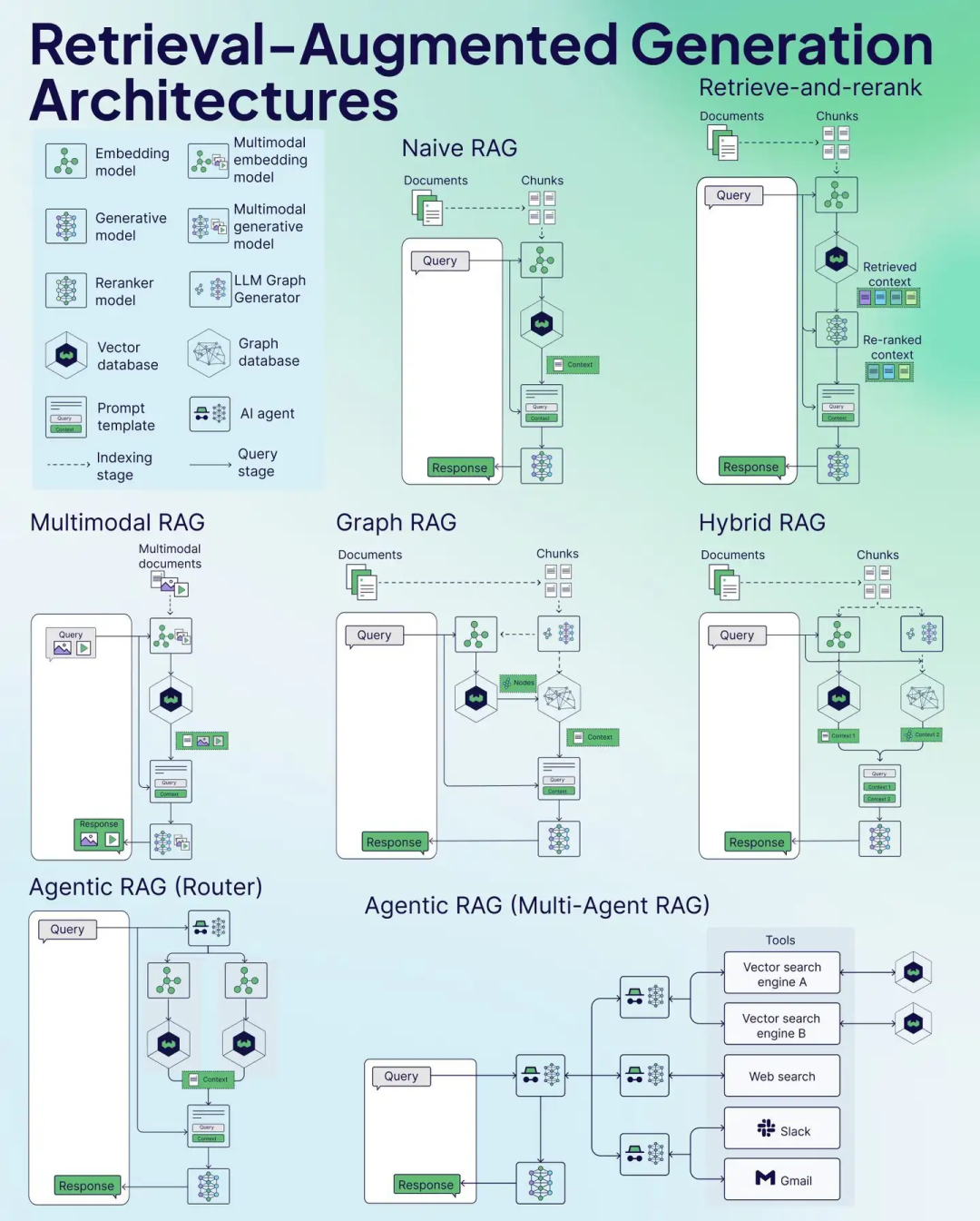
1. Naive RAG(朴素RAG)
核心原理:基于文档分块检索,直接将检索结果输入生成模型生成答案,包含检索模块(向量/关键词搜索)和生成模块(LLM)。 优点:简单易实现、低延迟、模块化设计。 缺点:检索结果质量不稳定、缺乏上下文整合、易受噪声影响。 适用场景:基础问答、小型知识库、对精度要求不高的场景。
2. Retrieve-and-Rerank RAG(检索与重排序RAG)
核心原理:在Naive RAG基础上增加重排序模块(如Cross-Encoder或BERT模型),优化检索结果相关性。 优点:提升生成质量、减少噪声干扰、支持领域优化(如法律/医学)。 缺点:计算成本增加、依赖重排序模型性能。 适用场景:高精度问答(法律文档、技术文档)。
3. Multimodal RAG(多模态RAG)
核心原理:支持多模态数据(文本、图像、视频等)的检索与生成,利用跨模态模型(如CLIP)对齐语义。 优点:信息表达丰富、支持跨模态查询(如图像问答)、增强上下文理解。 缺点:实现复杂、计算资源消耗高、需多模态训练数据。 适用场景:电商推荐、医疗影像分析、多模态内容生成。
4. Graph RAG(图RAG)
核心原理:利用图数据库(如Neo4j)存储实体关系,通过图查询实现多跳推理和语义关联检索。 优点:捕捉复杂关系(因果、层级)、支持动态更新、增强推理能力。 缺点:图构建和维护成本高、依赖图数据质量。 适用场景:知识图谱问答、科研文献分析、复杂关系推理(医学/法律)。
5. Hybrid RAG(混合RAG)
核心原理:结合多种检索策略(如向量检索+关键词检索+图检索),融合结果后生成答案。 优点:检索覆盖率高、灵活适配多场景、抗噪声能力强。 缺点:系统复杂度高、需协调多模块权重。 适用场景:知识库质量参差不齐、需多策略互补的场景。
6. Agentic RAG (Router)(路由RAG)
核心原理:通过智能路由器(基于LLM)动态分配查询至不同模块(如专用知识库、API等)。 优点:动态负载均衡、支持多数据源、模块扩展性强。 缺点:路由策略设计复杂、多模块整合难度高。 适用场景:多任务类型(跨API/数据库)、企业知识管理。
7. Agentic RAG (Multi-Agent)(多智能体RAG)
核心原理:多个智能体协同处理任务(如并行检索数据库、搜索引擎、邮件系统),整合结果生成答案。 优点:高度模块化、并行处理效率高、支持复杂任务自动化。 缺点:代理协作机制复杂、通信开销大。 适用场景:超大规模任务(多轮对话、跨工具协作)。
对架构选择的建议
基础场景:优先选择Naive RAG或Retrieve-and-Rerank,平衡速度与精度。 多模态需求:采用Multimodal RAG,结合CLIP等跨模态模型。 复杂关系推理:Graph RAG或Hybrid RAG更适合知识图谱和结构化数据。 动态任务分配:Agentic RAG系列适用于多数据源、多工具集成的企业级应用。
扩展工具与资源
Weaviate部署:通过Docker快速部署并集成LangChain实现RAG流程。 优化技巧:使用混合搜索( alpha参数调优)、查询重写(Query Rewriting)、自剪枝(Autocut)提升生成质量。开源框架:参考TrustRAG项目实现模块化设计。
Spring Boot 集成 LLM 的 RAG(Retrieval-Augmented Generation)架构框架、技术选型与核心工作流
Springboot使用RAG的流程一般是这样的:
用户请求 → Spring Boot 应用 → 检索模块(Weaviate) → 生成模块(LLM) → 返回回答
↑
数据预处理(分块/向量化) → 向量数据库
RAG 系统分为三大核心模块
数据预处理模块
负责文档加载、解析(PDF/Word/HTML等)、分块(按段落、句子或固定长度)和向量化。 支持多模态数据(文本、图像等)的分块和向量生成。
检索模块
基于向量数据库(如 Weaviate)实现语义搜索,支持混合检索(向量+关键词)。 可选重排序(Reranking)模块优化检索结果。
生成模块
集成大语言模型(LLM),将检索到的上下文与用户查询结合生成最终回答。 支持多种 LLM 服务(如 OpenAI、本地部署的 Llama 3 等)。
核心工作流
1. 数据准备阶段
文档解析:从本地文件、数据库或 API 加载原始文档。 分块处理:根据语义或固定长度切割文档,保留元数据(来源、时间等)。 向量生成:调用嵌入模型(如 OpenAI text-embedding-3-small)生成块向量。向量存储:将向量与原始文本存入向量数据库,建立索引。
2. 用户查询阶段
查询向量化:将用户输入转换为向量。 上下文检索:
通过向量数据库检索 Top-K 相关文档块。 可选重排序模型(如 Cohere Rerank)优化结果。
3. 回答生成阶段
Prompt 构建:将用户查询与检索结果组合为 LLM 输入,例如:
“基于以下上下文回答问题:
[上下文1] ...
[上下文2] ...
问题:{用户输入}”
模型调用:发送 Prompt 至 LLM,配置生成参数(温度值、最大长度等)。 结果后处理:过滤敏感内容、格式化输出(如 Markdown 表格、列表)。
技术选型建议
1. 向量数据库
Weaviate:支持多模态、内置混合搜索(BM25 + 向量)、低延迟,适合复杂查询场景。 Qdrant:轻量级、高吞吐量,适合中小规模部署。 Milvus:分布式架构,适合超大规模数据(亿级向量)。
2. LLM 服务
云端 API:OpenAI GPT、DeepSeek。 本地部署:Ollama、vLLM。
3. 数据分块策略
固定长度分块:简单但可能破坏语义(如 512 字符)。 语义分块:基于 NLP 模型(如 Sentence-BERT)识别段落边界。 多粒度分块:结合粗粒度(文档级)和细粒度(段落级)提升召回率。
4. 检索策略
纯向量检索:适合语义相关性强的场景(如问答)。 混合检索:结合向量与关键词(BM25),提升多样性和覆盖率。 图增强检索:集成知识图谱(如 Neo4j)支持多跳推理。
扩展与优化方向
性能优化 :
异步处理分块和向量生成。 缓存高频查询结果(如 Redis)。
质量提升 :
引入自检机制(Self-RAG)让 LLM 评估自身回答的可靠性。 动态调整检索范围(如小范围精确检索 + 大范围兜底检索)。
安全与合规 :
敏感信息过滤(如 PII 数据脱敏)。 审计日志记录查询和生成过程。

